
들어가기 앞서
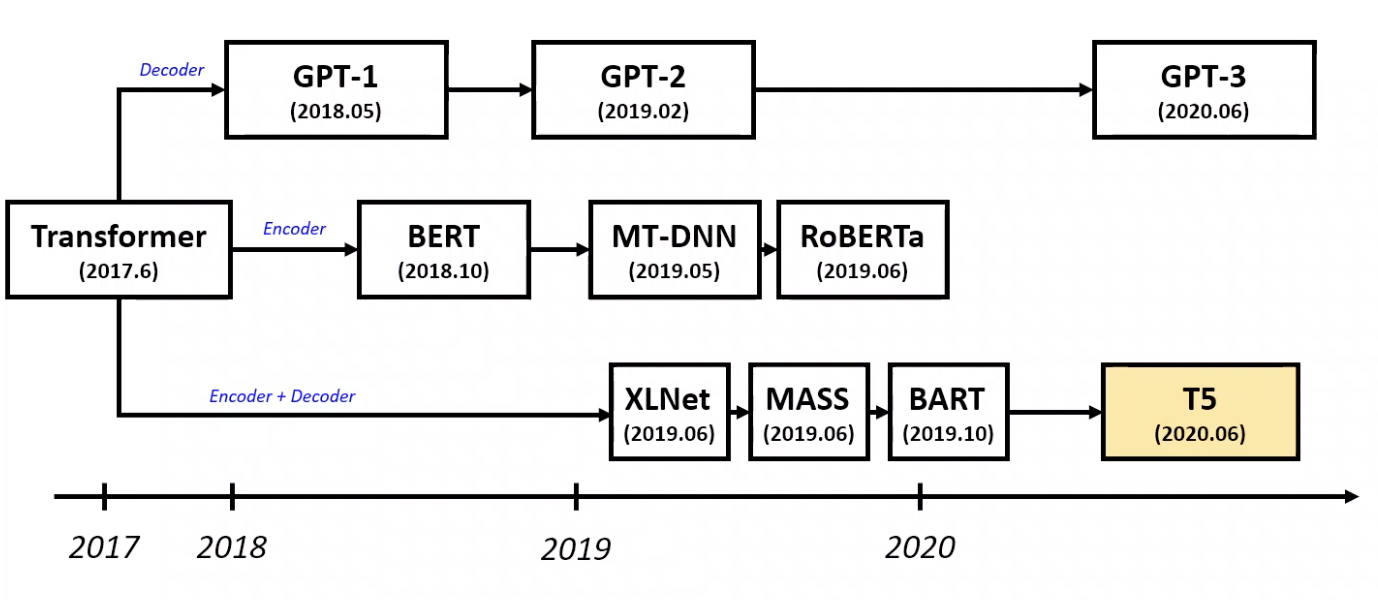
Attention is All your need 라는 Transformer라는 논문이 나온 후 대부분의 논문들이 Transformer를 기반으로 하여 작성이 됐음
Decoder만 사용하는 GPT계열, Encoder를 사용하는 BERT계열, 그리고 Encoder와 Decoder를 함께 사용하는 seq to seq 계열인 BART와 T5가 나옴.
이처럼 transfer learning framework 안에서도 다양한 모델이 존재함. 우리가 모델이라고 부르는 것 안에는 학습 방식 외에도 학습에 사용한 데이터셋, optimizer, 모델의 크기 등 많은 내용이 함축되어있음. 그래서 각 모델의 아이디어중 과연 “어떤 특징이 좋은 모델 성능을 내는데에 도움이 되었을까?”에 대한 질문의 답을 찾기위해 고안하여 나온 framework이다.

MODEL
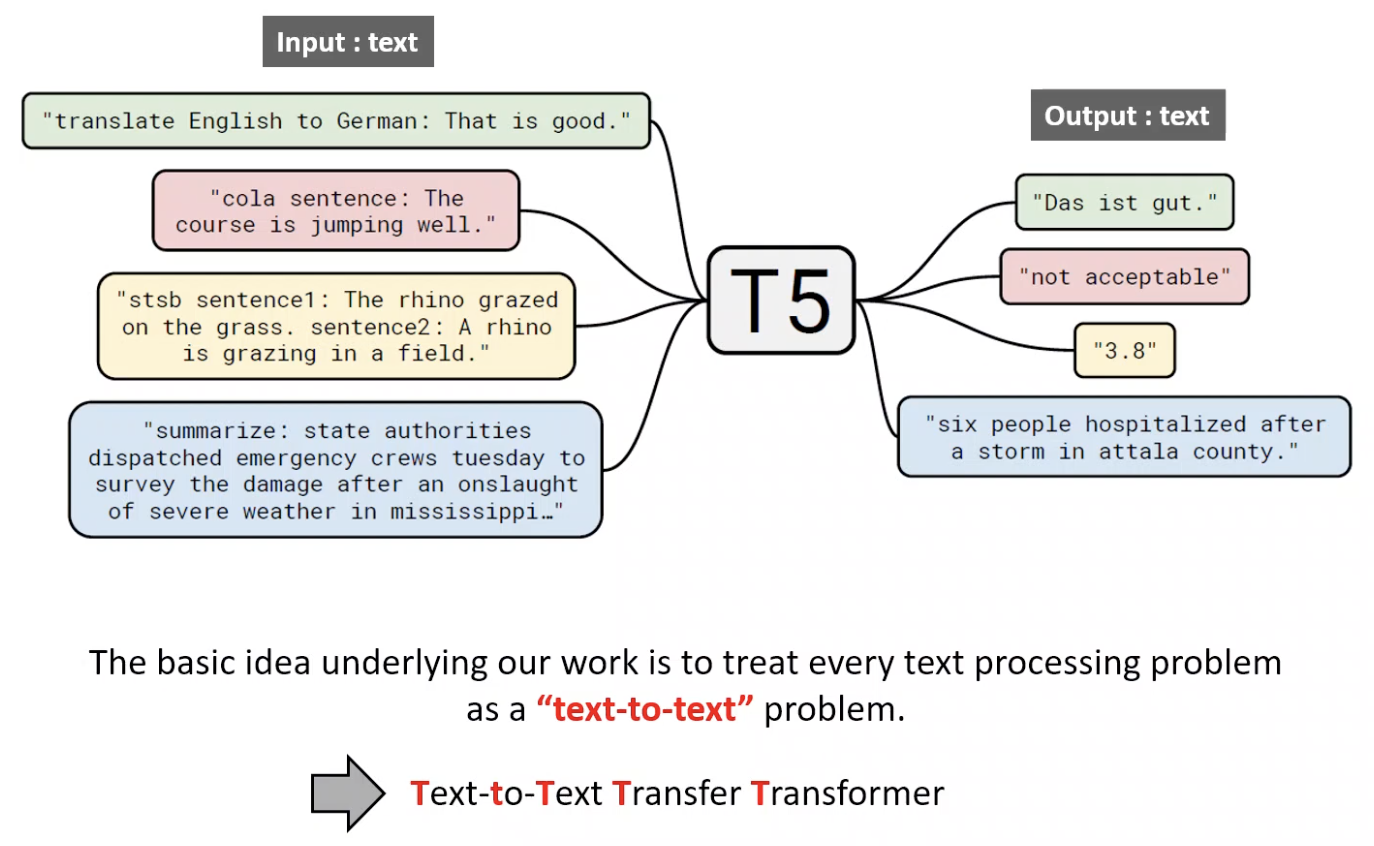
input과 output값이 text형식인 것을 확인할 수 있음.
이처럼 논문에서 모든 text를 처리하는 문제를 Text-to-Text로 바라봤고, 위 글씨처럼 T가 5개라 T5라 불림
- 모든 NLP task를 “test-to-text” task 관점에서 바라봄
- text-to-text 접근 방식을 사용하면 동일한 model,objective,training procedure, decoding process사용 가능
- 본 논문에서는 새로운 방법론을 제안하기 보다 survey,exploration 등 기존에 존재하는 기술들을 비교하여 다양한 실험들을 진행하여 나온 결과들을 보고함.
- T5는 모든 task를 transformer의 building block으로 하는 seq2seq framework이다.
- 기존 encoder decoder와 다르게 sequence X가 입력되면 sequenceY가 출력되는 것일뿐이라 생각하면 된다.
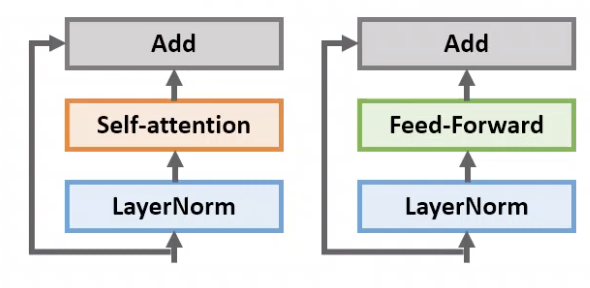
- T5 model에 대해 설명하자면 일반적인 encoder-decoder Transformer의 구조를 따름
- Layer Normalization
- input sequence의 token이 임베딩으로 매핑되어 encoder의 입력으로 들어가게 되면, N개로 쌓여진 인코더의 block에서 2개의 과정을 수행하게 됨.
- Self-attention 과 Feed-Forward를 진행하게 됨. 이때 self-attention,feed-forward network앞에 위치
- LayerNorm bias 적용을 하지 않음
- LayerNorm 이후 residual skip connection을 수행하게 됨
- Dropout
- feed-forward network내부, skip connection, attention weights, input/output 전체 stack에 적용
- Dropout rate: 0.1
- Position Embedding
- Original Transformer: Transformer에서는 sin position signal을 사용, BERT에서는 learned position embeddings을 사용.
- T5 : relative position embeddings을 사용
- input 사이에 pair-wise relationship을 고려함
- 각 토큰 위치 별로 고정된 encoding을 주고 attention을 계산하는 것이 아닌, self-attention 내에서 “key와 “query” 사이 relative position embedding 값을 준 것
- ex) BERT의 경우 sequence길이가 512이면 0~511까지 sequence id를 부여한다음 임베딩 값을 부여했는데, T5에서는 각 token의 상대적인 위치를 나타내는 임베딩을 사용함.
- Self-attention score + relative position embedding 값을 최종 score로 취함.
Pre-training DATASET
- Clossal Clean Crawled Corpus (C4)
- Pre-training dataset
- Unlabeled text data
- Common Crawl 데이터셋을 발전시켜 사용
- Common Crawl이란 n-gram language model 훈련 시 많이 사용된 웹 크롤링 데이터
- 한 달에 20TB 수집
- 전처리 후 학습에 사용된 데이터 총 750GB
- Tensorflow datasets에서 사용 가능
- 데이터 정제 과정
- Heuristic clean up 을 통해 텍스트 정제 진행
- .,!,?,””로 끝나는 문장만 사용
- 5문장보다 적은 페이지는 제거하고, 적어도 3단어 이상 포함된 문장만 사용
- 나쁜 단어 포함된 문장 제거
- Javascript 단어 들어간 라인 제거
- 자연어가 아닌 {}와 같은 프로그래밍 언어 포함된 것 제거
- 대부분 downstream task가 영어로 longdetect을 사용하여 영어일 확률이 0.99이하인 것들은 제거
- 이러한 Heuristic 방식은 기존 Common Crawl에서 영감을 받음, 기존 데이터 셋은 filtering에 제한적이고 공개적으로 사용할 수 없어 새로운 데이터셋을 구축함.
- Heuristic clean up 을 통해 텍스트 정제 진행
Downstream Tasks
- GLUE,SuperGLUE, 요약, QA, 번역 등 모델의 성능을 실험하기 위해 다양한 테스트를 진행함
T5에서의 input과 output 형식
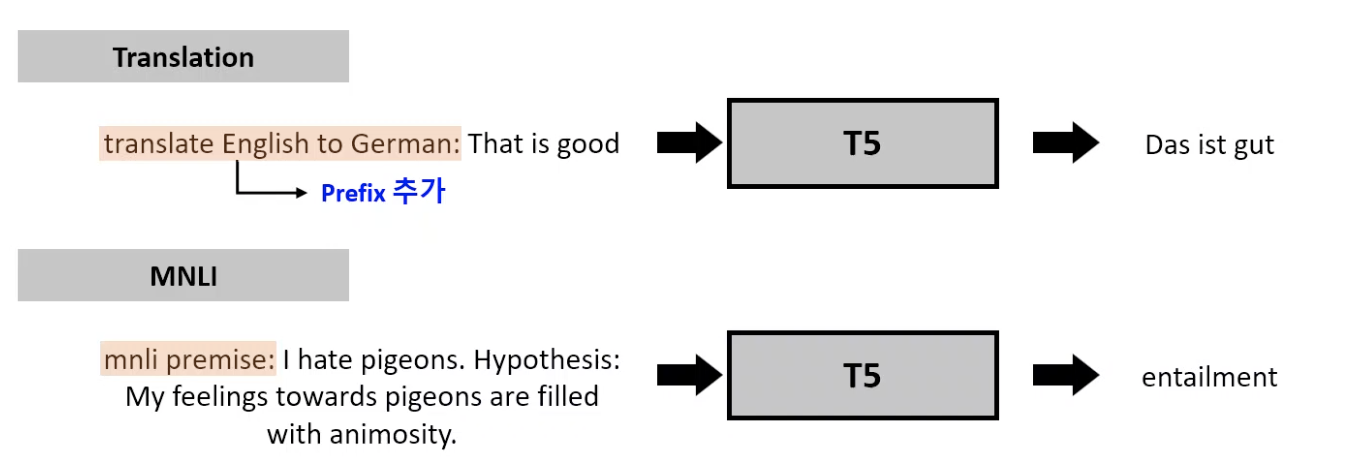
- Text-to-Text인 만큼, 입력값에 진행하고싶은 특정 task에 대한 정보를 기입하고자 Prefix를 추가함.
- 즉, orginal input sequence에 prefix를 추가함.
- 모든 task 를 “test-to-text” 모델로 처리하기 위해 특정 task는 몇 가지 트릭을 사용함.
- MNLI (Multi-Genre Natural Language inference corpus)
- GLUE task중 하나로 classfication task중 하나임
- 전제 문장과 가설 문장 쌍으로 구성되며, 전제 문장을 기준으로 가설 문장이 entailment,contradiction,neutral에 해당하는지 판단함.
- 정답 후보 라벨 외 “hamburger”와 같은 단어가 엉뚱한 단어가 생성될 경우 정답이 틀렸다고만 하고 다른 어떤 행위를 하지 않음.
- STS-B(Semantic Textual Similarity Benchmark)
- Regression task
- 문서 쌍 간 의미적 유사도 1-5 스코어로 측정함.
- 대부분의 스코어가 0.2단위로 증가/감소가 진행됨.
- Regression 문제를 21-class classification 문제로 변환하여 진행함.
- WNLI(Winograd Natural Language Inference)
- Winograd tasks(WINLI from GLUE, WSC from Super-GLUE)
- 대명사가 주어진 문장에서 어떤 대상인지 선택
- input: “The city councilmen refused the demonstrators a permit because “they” feared violence.”
- Target: “The city councilmen”
- MNLI (Multi-Genre Natural Language inference corpus)
Baseline
- “standard Transformer using a simple denoising objective”를 사용하여 Transformer모델을 선학습함.
- downstream task를 통해 fine-tuning을 진행함.
- encoder-decoder 구조가 generative나 classification task에서 모두 좋은 성능을 보임
- base- BERT configuration과 동일하게 구성함.
- Training
- 모든 task는 text-to-text 형태를 따름
- Maximum likelihood와 cross-entropy loss로 학습을 진행함
- Optimization으로는 AdaFactor를 사용
- Greedy decoding을 사용(매 timestep마다 가장 확률이 높은 logit을 선택함)
- Vocabulary
- SentencePiece 라이브러리를 이용하여 WordPiece 진행함.
- 32,000개 단어를 진행함
- Fine-tuning시 번역 task도 있어 영어 외의 언어도 커버가 필요함(German, French, Romanian)
- C4 데이터셋의 1/10 사이즈로 각 언어 말뭉치를 추가하여 WordPiece를 진행함.
- Unsupervised Objective
- 이전에는 선학습 할 때 casual language modeling objective가 많이 사용되었으나, 최근에는 denoising objective가 좋은 성능을 보여주고 있음
- Denoising objective
- BERT의 “masked language modeling” objective와 같이 입력 시퀀스의 15% 토크 임의로 마스킹
- 연속적인 토큰을 1개로 마스킹
- Target은 Input에서 마스킹되지 않은 부분을 맞춰야 함.

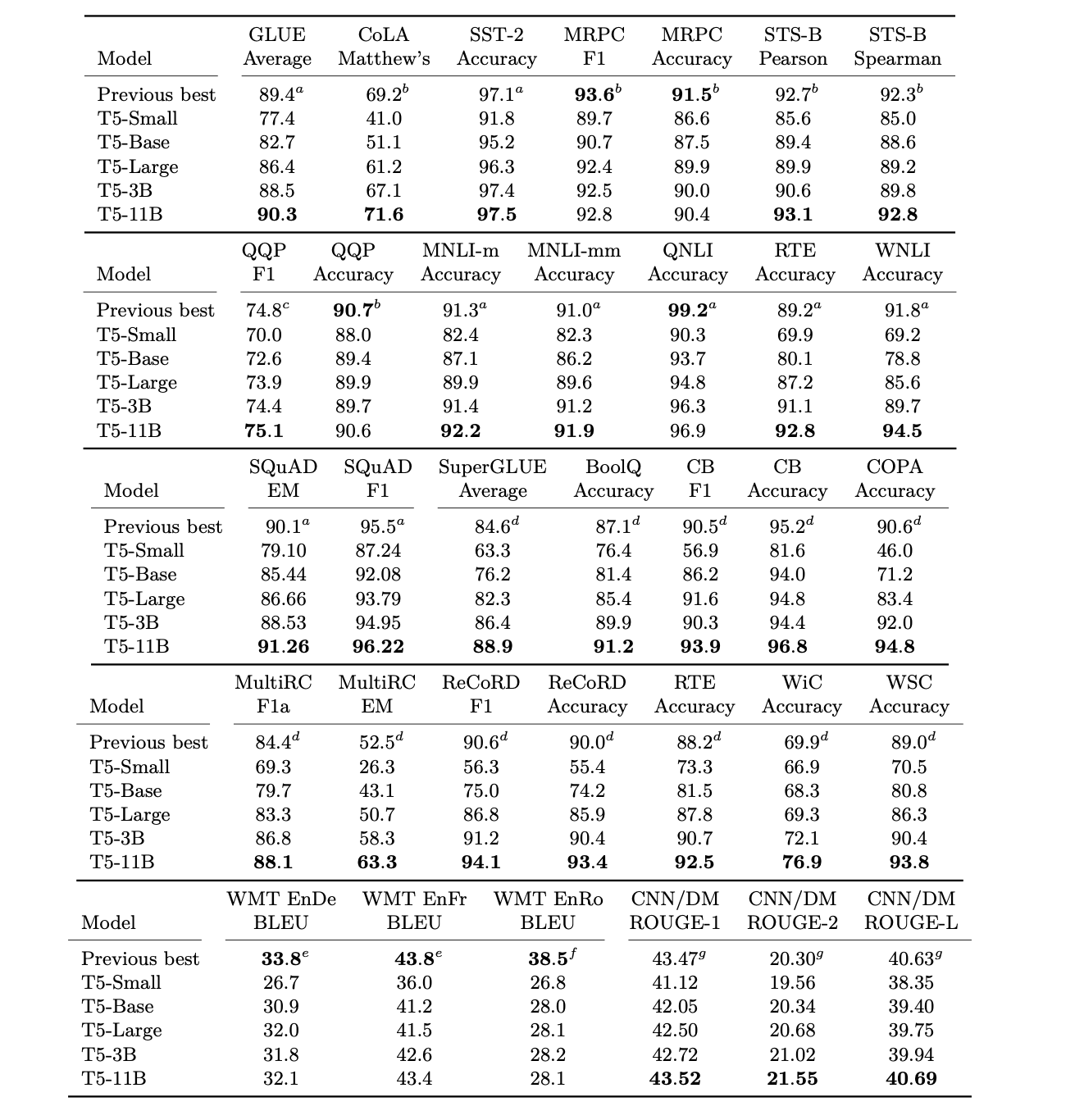
성능 비교

- 10개의 baseline을 학습시켜 평균과 표준편차를 확인함
- Random initialization ,data set shuffling 을 다르게 설정함
- GLUE,SuperGLUE의 경우 모든 subtask 성능에 대한 평균 점수
- base- BERT 보다 성능이 올랐으나 T5는 encoder-docoder 모델이고, 1/4 steps만 선학습 진행했기 때문에 직접적으로 비교하긴 어려움.
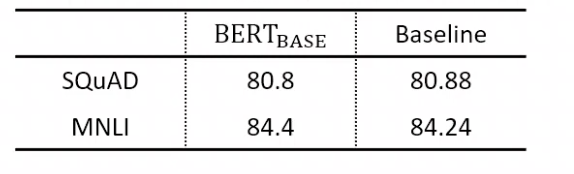
- 선학습은 성능 향상에 효과적임.
Pre-training architecture
다양한 transformer architecture들에 대해 비교 실험을 진행함.
- Model structures
- 모델의 attention 메커니즘에서 “mask”의 다양한 구조를 비교함
- Fully-visible
- Causal
- Causal with Prefix
- 모델의 attention 메커니즘에서 “mask”의 다양한 구조를 비교함
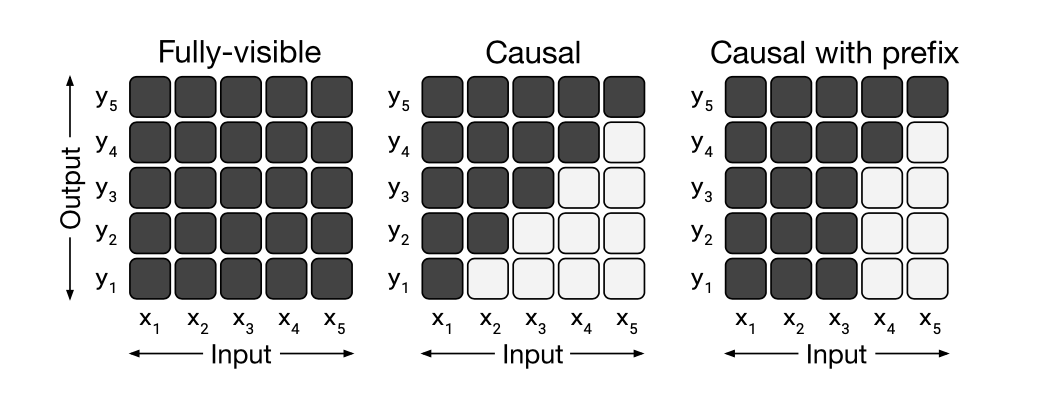
- Fully- visible
- Transformer encoder에서 사용 ex)BERT
- Query가 모든 Key에 attention 가능
- Causal
- Transformer decoder에서 사용 ex GPT
- Query가 현재 시점 포함 이전 timestep의 Key에 attention 가능
- 미래 시점에 있는 단어는 볼 수 없음
- Causal with prefix
- 입력 텍스트인 prefix로 주어진 부분은 fully-visible
- 출력 텍스트는 causal

-
- Encoder-Decoder
- 인코더는 fully-visible attention을 적용하였고 decoder만 causal attention을 적용함.
- Language model
- 전부 causal attention이며, 이는 uni-directional하게 정보를 습득하는 것을 나타냄
- Prefix LM
- encoder-decoder와 유사한 것으로 보임. input인 x에 대해서는 bi-directional하게 정보를 습득하고 y만 causal attention이 적용됨.
- 모든 모델의 입력과 출력은 text와 text임. building block은 transformer이며, block과 block을 연결하는 attention 방식이 위 모델 3가지 방식임을 볼 수 있음.
- Encoder-Decoder
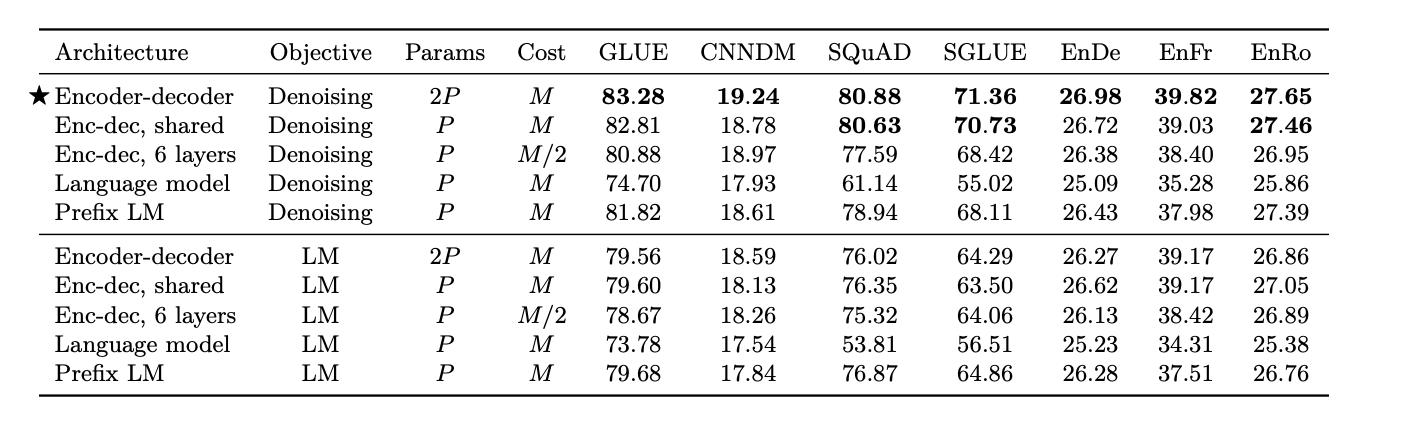
- Result
- Encoder-decoder architecture with the denoising objective performed best
- 인코더와 디코더 파라미터 공유하는 것은 성능 차이가 크게 나지 않음.
- Layer를 줄이는 것은 성능에 악영향을 끼침
- Denoising objective를 사용하는 것이 language modeling objective보다 높은 성능을 나타냄.
Pre-training objective
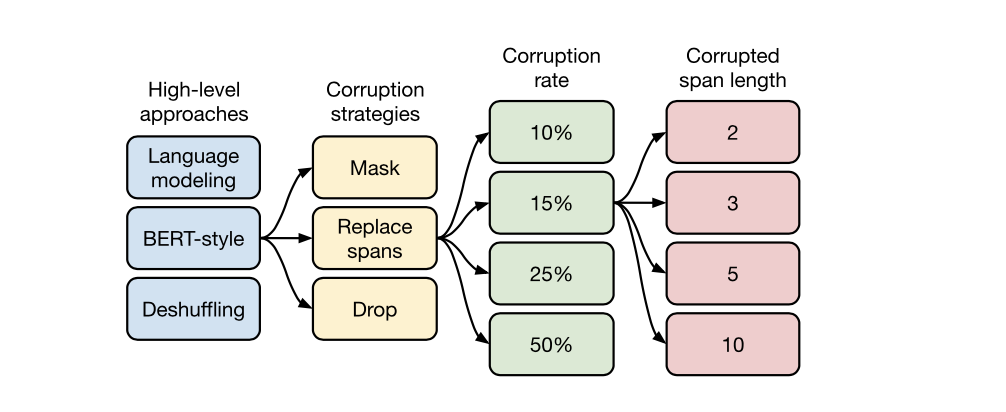
- Unsupervised Objective

- Objective는 text-to-text encoder-decoder에 맞게 변환함.
- Prefix language modeling : input으로 문장 앞부분 넣으면 target에서 문장의 뒷부분 예측
- BERT-style : 토큰의 15%를 마스킹, 90%를 랜덤 토큰으로 교체
- MASS-style : BERT-style에서 90% 랜덤 토큰으로 교체하는 방법만 제외
- l.i.d .noise,replace spans: masking되지 않은 부분 예측
- l.i.d .noise,drop tokens : masking을 알려주지 않아도 빠진 문장 예측
- Random spans : span이 1개가 아니라 더 긴 span 예측
Conclusion
- Text-to-text
- text-to text framework 사용하여 하나의 모델로 다양한 태스크 학습 가능
- Architectures
- Encoder-Decoder 구조 사용
- Unsupervised objectives
- Denoising objectives 사용
- Data sets
- Colossal Clean Crawled Corpus (C4) 데이터셋
- Scalling
- 모델의 크기를 키울 때 어떻게 해야 효과적인지 실험함.
- Pushing the limits
- 위의 방법 모두 사용, 11B 파라미터의 큰 모델을 학습시켜 다양한 task에서 SOTA 달성.
위의 여러 실험들의 결과를 종합하면,
1) Encoder-Decoder architecture
2) Span prediction objective
3) C4 dataset
4) Multi-task pre-training
5) Bigger models trained longer
의 구조로 학습할 때 가장 좋은 transfer learning 효과를 얻을 수 있다.
'AI > 논문분석' 카테고리의 다른 글
| ViT: An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale - 논문리뷰분석 (0) | 2023.02.07 |
|---|---|
| Noisy student training -논문리뷰 분석 (0) | 2023.02.07 |
| Attention Is All You Need 논문 리뷰 분석 (0) | 2022.11.03 |