
반응형
Noisy student training -논문리뷰 분석
논문이 나오기 전
- 기존 SOTA 비전 모델들이 지도학습을 위주로 많이 나왔으며 labeled Data를 바탕으로 한 모델들이 많이 나왔습니다.
- 따라서 모델의 성능을 높이기 위해선 더 많은 Labeled Dataset이 필요했고 모델의 성능이 한정이 있었습니다.
- 또한 Unlabeled Dataset을 잘 사용하지 못하였습니다.
무엇을 이뤘는가?
- 방대한 양의 Unlabeled Dataset을 효율적으로 사용하여 모델 성능을 높였습니다.
- teacher network와 동등하거나 보다 큰 student network를 만들고 student network에 noise를 주입함으로써 모델을 보다 견고하게 만들었습니다.
- 준지도학습 접근법으로 다음과 같은 단계를 밟습니다.
- teacher 모델에게 라벨링 된 이미지로 훈련을 합니다.
- teacher 모델을 사용하여 비라벨링된 이미지에 가짜 레이블을 만듭니다.
- 가짜 라벨 이미지와 라벨링된 이미지 두개를 student 모델에게 학습시킵니다.
- 다시 학습된 student 모델을 teacher로 사용하여 다른 student를 학습시킵니다.
- 위 3단계를 반복적으로 진행합니다.
- Noisy Studnet Training은 self-training과 distillation 2가지 방식을 향상시켰습니다.
- Student는 teacher보다 적어도 동일하거나 큽니다.
- Student에는 pseudo labeled image가 추가되었습니다.
- 추가적으로 student를 학습 할 때는 dropout,stochastic depth, data augmentataion과 같은 노이즈를 추가합니다.
학습 결과
- 해당 Noisy Student Training을 진행하면서 약 300M개의 비 라벨링된 이미지를 함께 사용했습니다.
- 이후 추가적으로 ImageNet-A,C,P에서도 test를 진행합니다.
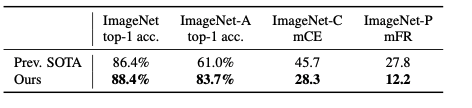
위 mCE와 mFR은 평균 손상 오차(mCE) 및 평균 플립 속도(mFR)입니다.
알고리즘

먼저 labeled image와 unlabeled image가 필요합니다.
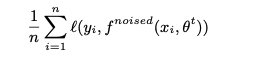
- labeled image로 teacher model을 학습시킵니다. 이때 손실함수는 labeled image의 cross entropy loss를 최소화 합니다. 이땐 노이즈를 이용하여 학습을 진행합니다.

- teacher model을 사용하여 unlabeled image에 대한 pseudo label을 생성합니다. 이땐 노이즈를 사용하지 않습니다.

- pseudo labeled image와 labeled image로 노이즈가 추가된 student model을 학습합니다. 이때 student model은 teacher 모델보다 크거나 같습니다.
- 위 과정을 반복합니다.
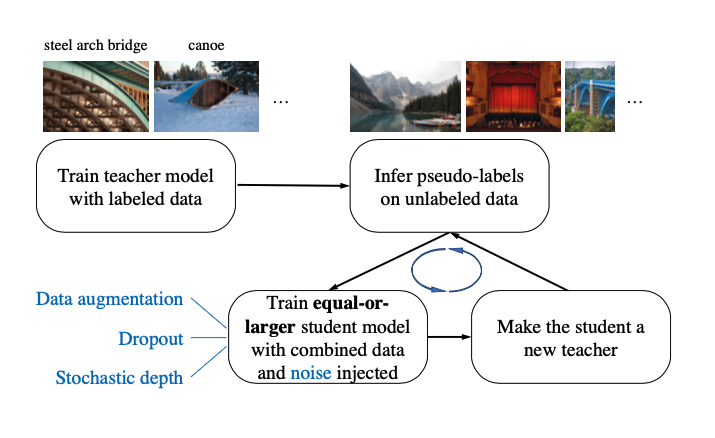
- teacher model로는 EfficinetNetB7로 사용했습니다.
- student model로는 EfficientnetL2로 사용했습니다.
모델 접근법의 중요한 특징
- Unlabled Data를 사용하기 전, Unlabeled Data에 Data Filtering 과 Balancing을 적용합니다.
- Data Filtering은 Labeled Data로 학습한 EfficientNet-B0모델로 추론한 결과를 바탕으로 confidence score가 0.3보다 높은 데이터만 가져오는 것을 말합니다.
- Data balacing은 Filtering이후 클래스당 최대 130K의 이미지를 갖는데, 클래스 균형을 맞추기 위해 130K보다 적은 클래스의 경우 랜덤으로 데이터를 복사해서 130K를 채워주는 것을 말합니다.
- 또한 2가지 타입의 노이즈를 사용합니다.
- input noise
- RandAugment와 함께 data augmentation을 사용합니다.
- 회전, 대비 등 14가지 augmentation 기법들 중 임의로 n개를 적용한 데이터 증강 기법입니다.
- model noise
- dropout과 stochastic depth를 사용합니다.
- dropout : 학습에서 신경말 일부 노드를 드롭하는 기법
- Stochastic Depth : 신경망의 Depth를 랜덤하게 줄이는 기법
- input noise
추가 설명
데이터 셋의 종류
- 라벨 데이터 : ImageNet 2012 ILSVRC challenge prediction task
- 비라벨 데이터: JFT dataset( 약 300M개)
논문내용 중 일부
- 위 논문에서는 “우리의 주요 개선 사항은 학생에게 노이즈를 더하고 교사보다 작지 않은 학생 모델을 사용하는 데 있다.” 라고 말합니다.
- 위 논문의 방법은 학생모델에게 학습할 수 있는 충분한 용량과 소음 측면에서 어려운 환경을 제공함으로써 학생이 교사보다 좋아지기를 바라는 ‘지식의 확장’이라고 생각할 수 있다고 말합니다.
- 학생이 고의적으로 노이즈를 만드는 경우, 거짓 label을 생성할 때 노이즈를 만들지 않는 교사와 일치하도록 훈련됩니다.
모델 결과
- 모델 성능 비교:
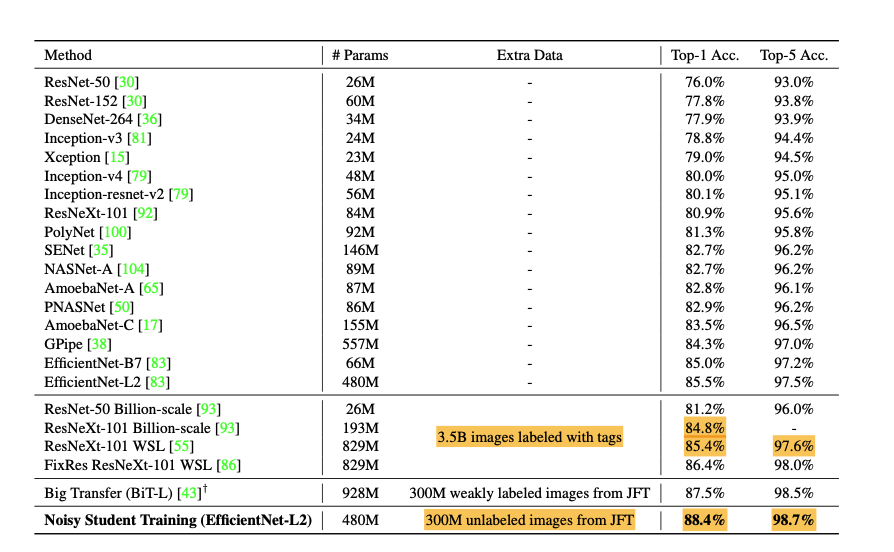
- iterative training을 하지 않았을 때 결과물:

ImageNet-A, C, P에 대한 견고함 결과물



- Noisy Training한 모델들이 mCE값과 mFR값이 낮게 나온 모습을 보실 수 있습니다.
- MCE는 다양한 손상에서 가중 평균 오류율이며, AlexNet의 오류율을 기준으로 합니다(낮을수록 좋습니다).
- mFR은 AlexNet을 기준으로 예측이 뒤집힐 확률을 측정한다(낮을수록 좋다).
- 검은색 글씨: Noise student training한 모델
- 빨간색 글씨: 기존 모델


- 위 표에서 나타나는 점
- Unlabeld Data가 클수록 좋다
- Noise가 있을수록 좋다.
- teacher model이 Unlabeled Data를 추론 시 noise는 추가하지 않는 것이 좋다.
결론
- 이전 지도학습 러닝은 SOTA Imagenet모델을 향상시키기위해 수억개의 labeled data가 필요했습니다.
- 해당 논문에선, 우리는 unlabeled image를 사용하면서 모델에 대한 견고함과 정확성을 발전시킬 수 있다는 것을 보여줬다고 말합니다.
- 우리는 student에게 noise를 추가함으로써 견고함과 정확성을 향상시켰고, 그러므로 이름을 Noisy Student Training이라 지었다고 말합니다.