Attention Is All You Need -논문리뷰 분석
RNN과 LSTM이란?
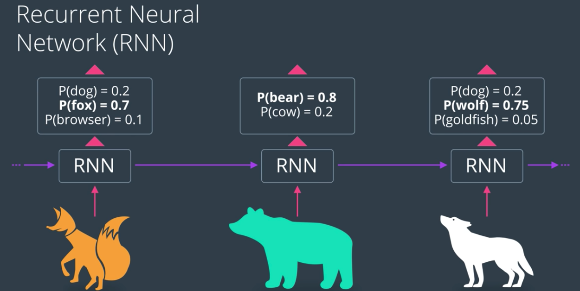
RNN: 학습했던 데이터를 그 다음 순서에 정답데이터로 사용해 (누적 학습의 개념) 학습을 이어간다. 그래서 시계열 + 동적인 특성을 갖는 데이터에게 적합하다. 즉, 다시 역전파(Backpropagation) 과정을 통해 순환적으로 학습을 진행합니다.
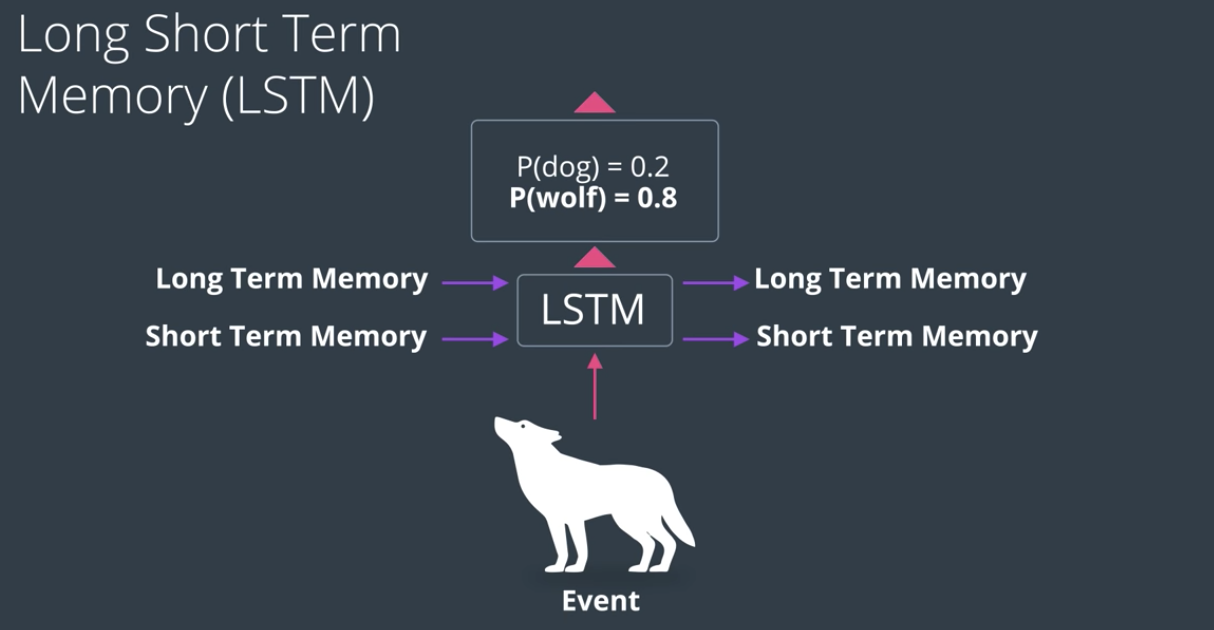
LSTM은 본격적인 연산 전에 장기 / 단기 정보를 담은 메모리를 분류하고, 이 메모리와 이벤트를 기반으로 각각 Long term memory, Short term memory에 적합한 내용을 따로따로 학습시킵니다. 아래의 그림에서 더욱 쉽게 이해할 수 있습니다.
들어가기 앞서 내용 설명
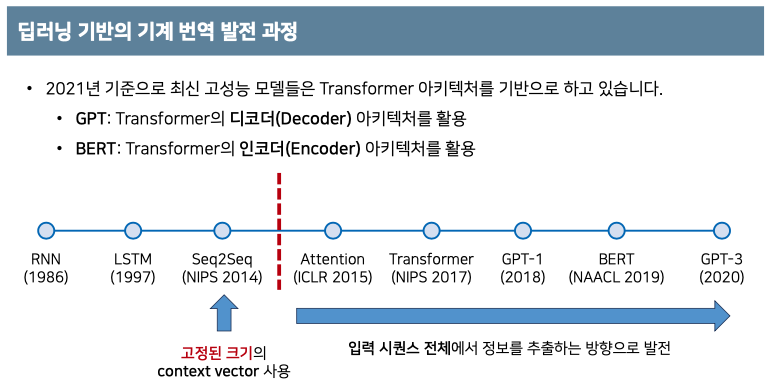
NLP의 기반이 되는 RNN과 LSTM이 나온 이후에 Seq2Seq가 나온 후 현대 NLP의 고성능 모델들은 Transformer 아키텍처를 기반으로 진행이 됐습니다. 그 전에 사용되었던 모델들은 context vector를 사용하였는데 이는 고정된 크기의 벡터를 바탕으로
디코더와 인코더가 진행되었습니다.
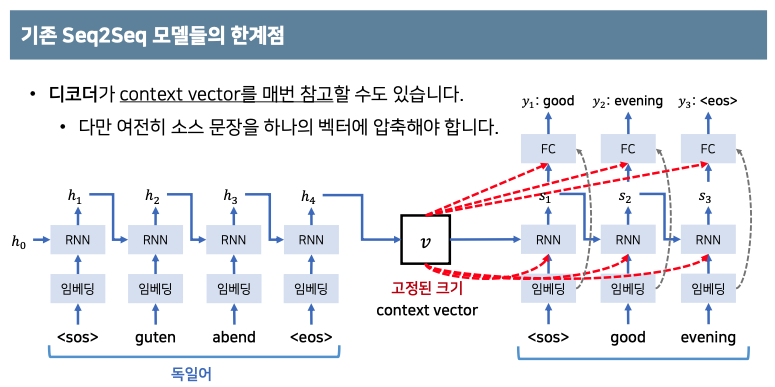
context vector에 소스 문장의 정보를 압축하여 병목현상(bottle neck)이 발생하여 성능하락에 원인이 되었습니다.
이러한 문제점들을 해결하고 보안하고자 나온 메커니즘이 attention메커니즘 입니다.
모든 소스 문장에서의 출력 전부를 입력으로 받고 이를 병렬적으로 처리합니다.
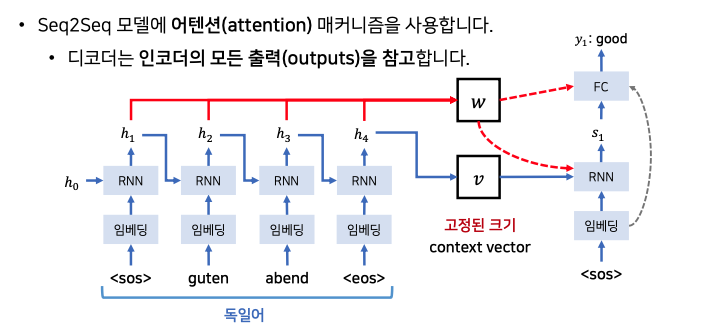
위 Seq2Seq 모델에서는 attention 메커니즘을 사용합니다.
attention 메커니즘이란?
어텐션의 기본 아이디어는 Decoder에서 출력 결과를 예측하는 매 시점(time step)마다, Encoder의 Hidden State를 다시 한 번 참고한다는 아이디어입니다.
그리고 이 참고하는 비율을, 해당 시점에서 예측해야하는 결과와 연관이 있는 부분을 판단하여 좀 더 집중 (Attention) 하여 본다고 하여 Attention Mechanism이라고 부릅니다.

디코더는 매번 인코더의 모든 출력중에서 어떤 정보가 중요한지 계산합니다. 이후 에너지는 디코더가 출력 단어를 만들때마다 인코더의 모든 출력을 고려합니다.
s: 이전에 단어를 만들때 사용했던 hidden state입니다.
h: 인코더의 hidden state입니다.
이후 소스문장에서 나왔던 모든 출력값중에서 어떤 값과 연관성이 있는지 구합니다.
본 논문에서는 가중치는 softmax 함수를 통해 가중치를 구합니다. 이때 문장내에 단어순서를 알려주기 위하여 positional Encoding을 사용하고 있습니다.
Softmax 함수란?
뉴런의 출력값에 대하여 class 분류를 위하여 마지막 단계에서 출력값에 대한 정규화를 해주는 함수입니다. 소프트맥스 함수의 특징은 결과물의 수치의 합은 언제나 1이 나와야합니다. 해당 정규화 된 값을 바탕으로 어느 결과물의 수치가 좀 더 비중이 큰지 계산할 수 있습니다.
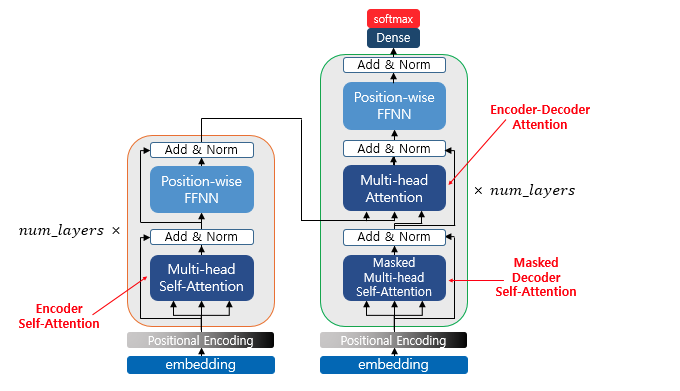
Transformer(트랜스포머)의 architecture
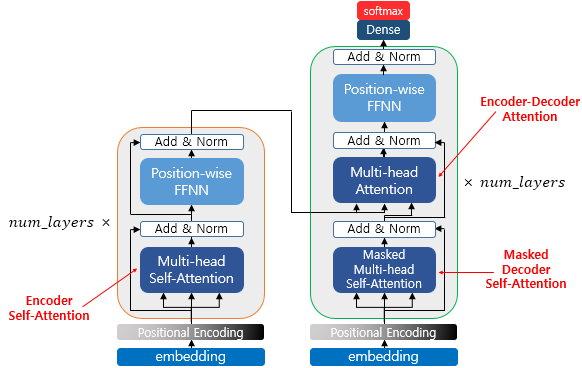
위에 보시다싶이 트랜스포머는 인코더와 디코더로 구성되어있습니다. 이때 num_layer 만큼 attention과정을 여러 레이어에서 반복합니다.
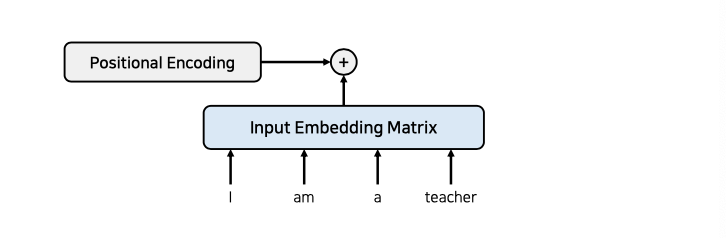
트랜스포머의 동작원리에 대하여 설명하자면 RNN을 사용하지 않으려면 위치 정보를 포함하고 있는 임베딩을 사용해야 하지만 이때 Positional Encoding을 사용하여 진행합니다.
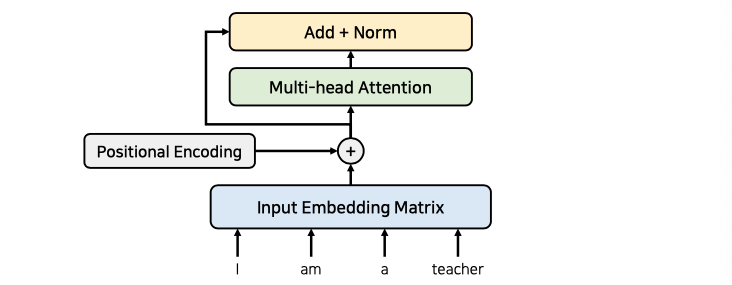
이후 성능향상을 위해 잔여 학습을 사용합니다. 즉, 과정을 건너뛴다고 볼 수 있습니다. 해당 과정을 통해 초기 모델속도가 향상됩니다.
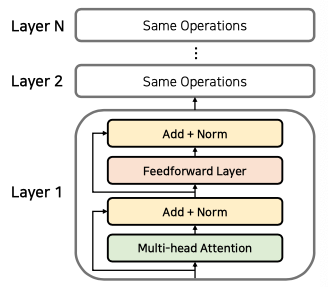
위 사진처럼 인코딩 과정에서 어텐션과 정규화 과정을 반복합니다. 이때 파라미터로
Multi-head Attention과 Feedforward Layer를 사용하는데 이는 각 레이어에서 다르게 사용됩니다. 이때 Layer를 중첩하여 사용하는 과정에선 Normaliztion을 진행 한 후 demension을 동일하게 맞춰줍니다.
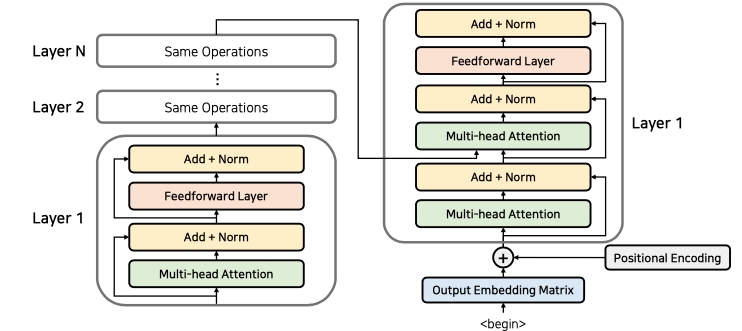
이후 Layer들을 중첩하여 계산하고 마지막 layer에서 나온 결과물은 디코더에 들어가게 됩니다. 디코더에서는 하나의 layer에서 2개의 multi-head attention 을 사용하게 되는데 처음 attention은 self attention으로 단어들의 가중치를 구한 후 출력되는 문장에 대한 전반적인 표현을 학습 할 수 있도록 만듭니다.
2번째 attention은 인코더의 정보를 사받아 사용하며 이때 소스문장에서의 어떤 정보와 연관성이 있는지 구할 수 있도록 진행됩니다.
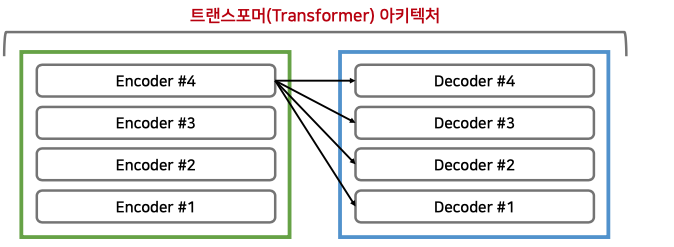
위 사진은 n_layer가 4라 가정했을 때 마지막 인코더 layer의 출력이 모든 디코더 레이어에 입력되는 과정을 보여드린 것입니다.
트랜스포머(Transformer)의 어텐션(attention)
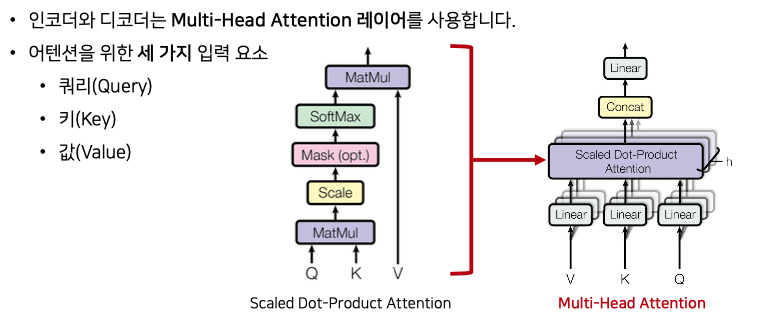
인코더와 디코더에서는 Multi -Head attention레이어를 사용합니다.
이떄 어텐션을 위해 세가지 입력 요쇼가 필요합니다.
- Query : 물어보는 주체입니다. ex) I
- Key : 연관되어 있는 주체입니다. ex) I am a teacher
- value : attention value값을 구하기 위해 계산된 값
Q와 K를 통해 softmax로 가중치 값을 구한 후 이때 V 와 곱하여 scaled dot-product attention을 구하게 됩니다.
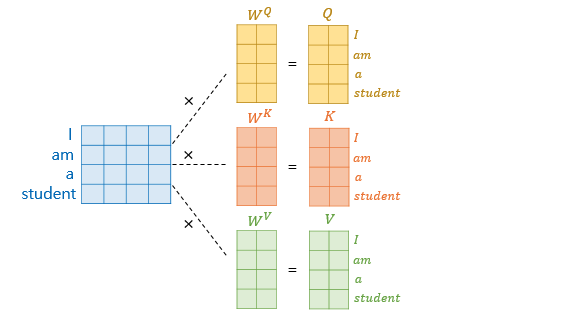
Q행렬을 K행렬을 전치한 행렬과 곱해준다고 해봅시다. 이렇게 되면 각각의 단어의 Q벡터와 K벡터의 내적이 각 행렬의 원소가 되는 행렬이 결과로 나옵니다.
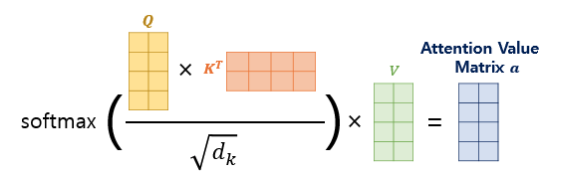
위의 그림의 결과 행렬의 값에 전체적으로 $\sqrt{d_{k}}$를 나누어주면 이는 각 행과 열이 어텐션 스코어 값을 가지는 행렬이 됩니다.

해당 논문에서 기재된 수식입니다. 위 수식을 설명하자면 Q와 K를 곱한 후 이를
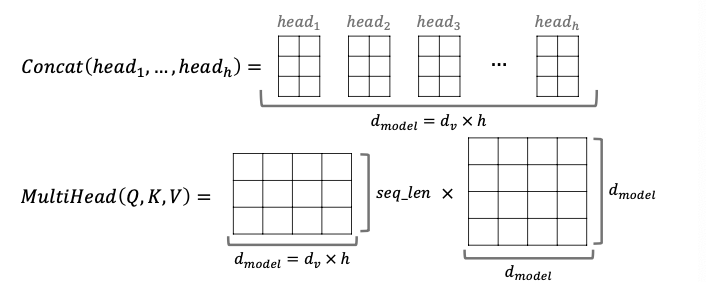
$\sqrt{d_{k}}$를 나누게 되면 attention을 구하게 됩니다. 이후 head의 개수만큼 각 head별로 독립적인 attention을 구하게 됩니다. 독립적인 attention을 구하여 다양한 값을 계산할 수 있도록 합니다. 이후 concat을통해 Linear를 계산하며 이를통해 demension이 줄어들지 않습니다.
디코더 파트에선 Add+norm을 통해 나온 값이 Query가 되고 인코더에서 들어오는 값이 key와 value가 됩니다.
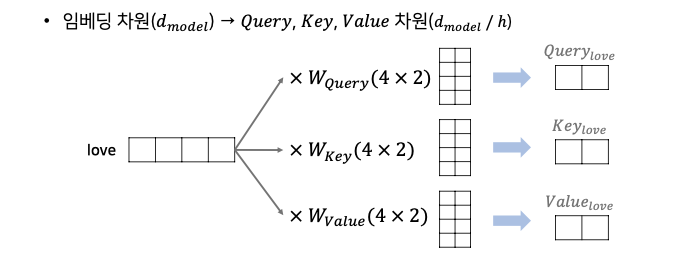
위 해당 내용에선 love가 4차원이라 가정하며 demension이 2라 가정했을 때 연산 과정입니다.
각 단어에 대한 query, key, love를 구합니다.
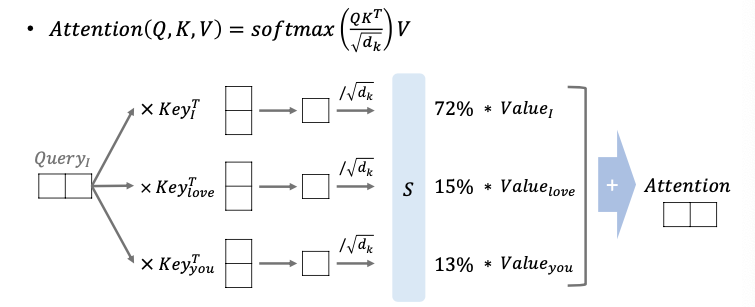
이후 해당 query 포인트와 key 값을 곱한 후 softmax함수를 통해 나온 결과값을 value와 곱하여 attention을 구하게 됩니다.
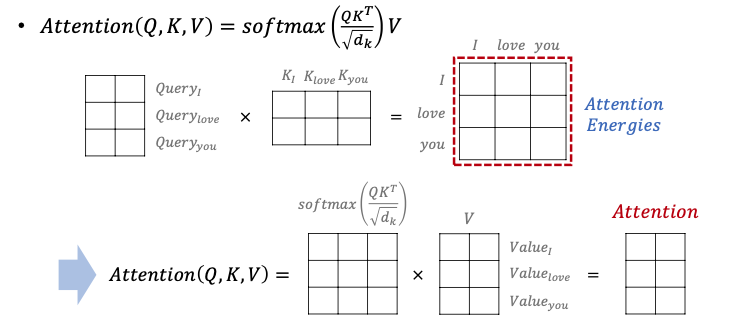
행렬의 특성을 이용하여 각 행,열 별로 정보를 갖게 한다음에 이를 matrix 곱센 연산을 통해 한번에 진행하도록 합니다.
이때 특정 단어를 무시할 수 있도록 할 수 있는데 마스크 행렬을 이용하여 특정 단어를 무시 할 수 있습니다
마스크 행렬이란?
특정 단어를 무시 할 수 있도록 함. Attention energy와 똑같은 크기의 행렬을 가진 Mask matrix를 만들어 이를 곱하여 특정 값이 무시될 수 있도록 만들 수 있음. 즉 0퍼센트에 가깝게 소프트맥스 함수의 값이 나올 수 있도록 만들 수 있음
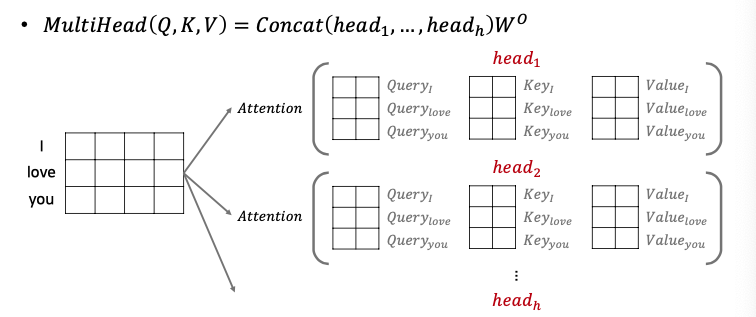
이후 concat함수를 통해 각 head 별로 나온 attention에 대한 정보를 이어붙인 후 dimension과 곱하여 차원이 동일하게 유지되도록 만듭니다.
위 논문에서 Postional Encdoing은 다음과 같은 주기함수를 활용한 공식을 사용합니다.
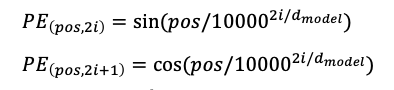
sin함수와 cos 함수를 이용하여 위의 수식에서 (pos, 2i) 일 때는 사인 함수를 사용하고, (pos, 2i+1) 일 때는 코사인 함수를 사용합니다. pos 는 입력 문장에서의 임베딩 벡터의 위치를 나타내며, i 는 임베딩 벡터 내의 차원의 인덱스를 의미합니다