
반응형
들어가기 앞서 기존 상태
- 트랜스포머 구조가 자연어 처리 task들에서 표준이 되는 동안, vision에 이를 적용한 사례는 한정되어 왔습니다. 비전 분야에서 attention은 Convolution network과 함께 적용되거나, Convolutional network의 특정 요소를 대체하기 위해 사용되었기 때문입니다.
- 해당 논문에선 이러한 CNN에 대한 의존이 필요하지 않고 순수 트랜스포머가 곧바로 이미지 패치들에 사용되고 이미지 분류에 잘 작동함을 보여줍니다.
Introduction
- NLP에서의 트랜스포머 스케일링이 성공한 것에 영감을 받아, 이 논문에서는 standard transformer를 최소한의 수정으로 직접 이미지에 적용하는 것에 대해 실험을 했습니다.
- 이를 위해, 이미지를 패치별로 쪼개고 (이미지 패치들은 NLP에서의 token과 같은 방식으로 다뤄지게 됩니다.), 이러한 패치들의 linear embeddings sequence 를 트랜스포머에 input으로 넣었습니다.
- 이 모델을 supervised 방식으로 이미지 분류에 학습을 시켜 실험하였다.
Inductive Bias
- training에서 보지 못한 데이터에 대해서도 적절한 귀납적 추론이 가능하도록 하기 위해 모델이 가지고 있는 가정들의 집합을 의미함
- 일반적으로 모델이 갖는 일반화의 오류(Generalization Problem)는 불안정하다는 것(Brittle)과 겉으로만 그럴싸 해 보이는 것(Spurious)이 있다. 모델이 주어진 데이터에 대해서 잘 일반화한 것인지, 혹은 주어진 데이터에만 잘 맞게 된 것인지 모르기 때문에 발생하는 문제이다. 이러한 문제를 해결하기 위한 것이 바로 Inductive Bias이다. Inductive Bias란, 주어지지 않은 입력의 출력을 예측하는 것이다. 즉, 일반화의 성능을 높이기 위해서 만약의 상황에 대한 추가적인 가정(Additional Assumptions)
이라고 보면 된다. - DNN의 기본적인 요소들의 inductive bias는 아래와 같음
- Fully connected: 입력 및 출력 element가 모두 연결되어 있으므로 구조적으로 특별한 relational inductive bias를 가정하지 않음
- Convolutional: CNN은 작은 크기의 kernel로 이미지를 지역적으로 보며, 동일한 kernel로 이미지 전체를 본다는 점에서 locality와 transitional invariance 특성을 가짐
- Recurrent: RNN은 입력한 데이터들이 시간적 특성을 가지고 있다고 가정하므로 sequentiality와 temporal invariance 특성을 가짐
- Transformer는 CNN및 RNN 보다 상대적으로 inductive bias가 낮음 (self attention을 기반으로 하고 있기 때문에)
- ViT에서 input이 patch단위로 들어오는 MLP(Multi-Layer Perceptron)는 locality와 translation equivariance가 있지만, CNN보다 image-specific inductive bias가 낮음
- 해당 모델에서 아래 두가지 방법을 사용하여 inductive bias의 주입을 시도함
- Patch extraction : 이미지를 자른 후 순서대로 기입
- Resolution adjustment: fine tuning을 할 때, patch의 크기를 동일하게 사용하지만, 이미지의 크기에 따라 patch 의 개수가 달라지므로, position embedding을 조정함.
개요
- 본 연구에서는 NLP에서 사용되는 standard Transformer를 이미지에 그대로 적용하여 이미지 분류에 좋은 성능을 도출한 Vision Transformer (ViT)를 제안함
- ViT는 이미지를 패치로 분할한 후, 이를 NLP의 단어로 취급하여 각 패치의 linear embedding을 순서대로 Transformer의 input으로 넣어 이미지를 분류함
- ViT를 ImageNet-1k에 학습했을 떄, 비슷한 크기의 ResNet보다 낮은 정확도를 도출하는 것을 통해 ViT가 CNN보다 inductive bias가 낮은 것을 알 수 있음
- 반면, ImageNet-21k와 JFT-300M에 pre training한 ViT를 다른 image recognition task에 transfer learning 했을 때, ViT가 SOTA 성능을 도출하는 것을 통해 large scale 학습이 낮은 inductive bias로 인한 성능 저하를 해소시키는 것을 알 수 있음
작동 방법
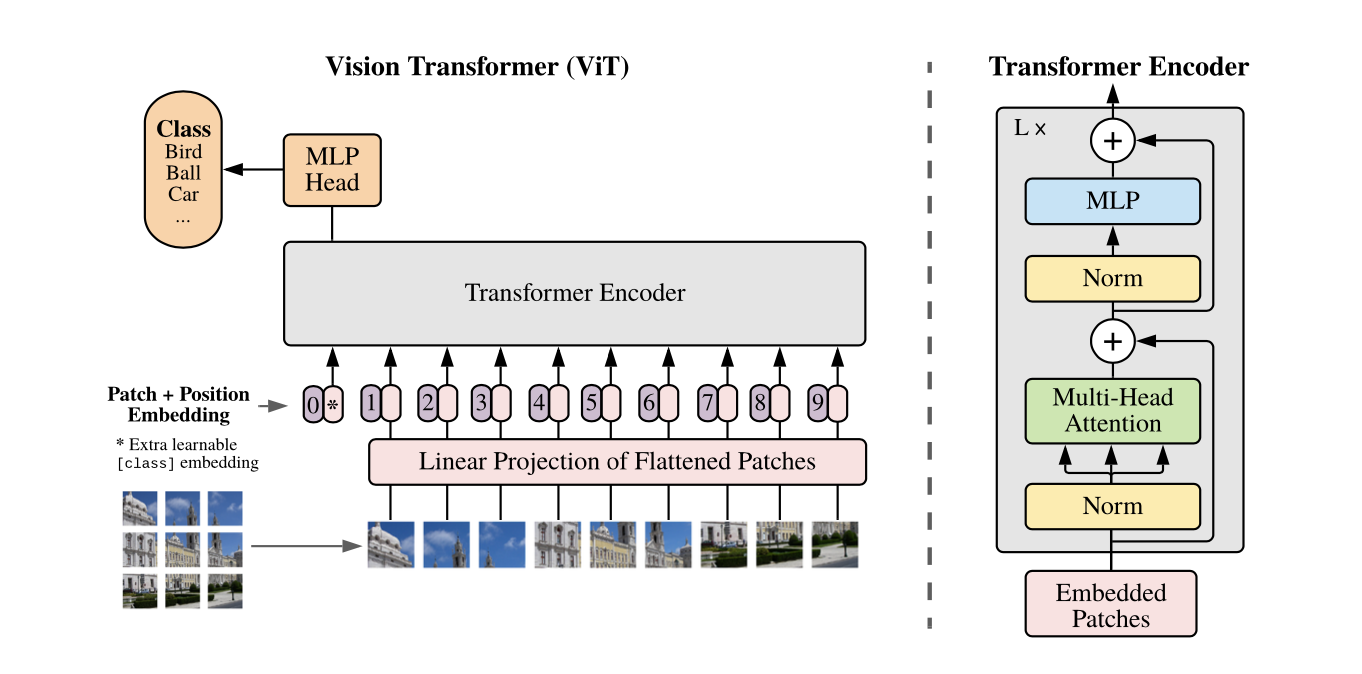
작동과정 5스텝
- 주어진 이미지에 대해서 이미지 x가 존재할 때, 이미지 x를 p by p크기의 정사각형 patch로 분할한 후에 patch sequence를 구축함.
- patch sequence가 구축되면, 왼쪽 위부터 오른쪽 아래로 순서대로 Trainable linear projection을 통해 분할한 각 patch를 flatten한 벡터를 D차원으로 변환한 후 , 이를 패치 임베딩으로 사용함.
- * 같은 Learnable class 임베딩과 패치 임베딩에 learnable position 임베딩을 더함
- 해당 임베딩을 Transformer encoder에 input으로 넣어 마지막 layer에서 class embedding에 대한 output인 image representation을 도출함
- 이를 MLP image representation을 input으로 넣어 이미지의 class를 분류함.
[ 이미지 인풋 ]
- 일반적인 Transformer은 토큰 임베딩에 대한 1차원의 시퀀스를 입력으로 받음
- 2차원의 이미지를 다루기 위해 논문에서는 이미지를 flatten된 2차원의 패치의 시퀀스로 변환함
- 즉, H x W x C → N x (P^2 x C) 로 변환
(H, W)는 원본 이미지의 크기, C는 채널 개수를 의미
(P, P)는 이미지 패치의 크기
N = HW/P^2 = 패치의 개수
- Transformer은 모든 레이어에서 고정된 벡터 크기 D를 사용하기 때문에 이미지 패치는 펼친 다음 D차원 벡터로 linear projection 시킴
- BERT의 [CLS]토큰과 비슷하게 임베딩 된 패치의 시퀀스에 z0 = x_class 임베딩을 추가로 붙여 넣음
- 이후 이 패치에 대해 나온 인코더 아웃풋은 이미지 representation으로 해석하여 분류에 사용
[ 위치 임베딩 ]
- 각각의 패치 임베딩에 위치 임베딩을 더하여 위치 정보를 활용할 수 있도록 함
- 학습 가능한 1차원의 임베딩을 사용
- 2차원 정보를 유지하는 위치 임베딩도 활용해 보았으나, 유의미한 성능 향상은 없었기 때문
Transformer Encoder

- ViT는 Multi-head Self Attention(MSA)와 MLP block으로 구성되어있음
- MLP는 2개의 layer를 가지며, GELU activation fuction을 사용함
- GELU activation function 이란?
- → 이것은 ReLU와 같은 또 다른 고성능 신경망 활성화이지만, 비선형성은 해당 뉴런 입력에 무작위로 ID 또는 제로 맵을 적용하는 확률적 정규화의 예상 변환을 나타낸다.
- Attention is all your need와 다르게 MLP와 multi-head attention 앞에 Layer Norm을 적용하고, 각 block뒤에는 residual connection을 적용함
Positional Embedding
- ViT에서는 아래 4가지 position 임베딩을 시도한 후, 최종적으로 가장 효과가 좋은 1D position임베딩을 ViT에서 사용함
- No positional information
- patch 임베딩만 transformer 인풋으로 사용
- 1-dimensional positional embedding
- input sequence , 패치를 3차원의 이미지가 존재할 때, 왼쪽 위부터 오른쪽 아래 순서대로 patch의 sequnce를 input으로 고려하는거.
- 2-dimensional postional embedding
- 3차원의 이미지에 대해서, 가로와 세로 축 2개로 two demesion으로 grid로 만들어서 input으로 사용
- Relative positional embeddings
- patch 들사이의 상대적인 거리를 사용한 positional embedding
- No positional information

Hybrid Architecture
- ViT는 raw image가 아닌 CNN으로 추출한 raw image의 feature map을 활용하는 hybrid architecture로도 사용할 수 있음
- Feature map은 이미 raw image의 공간적 정보를 포함하고 있으므로 hybrid architecture는 패치 크기를 1x1로 설정해도됨
- 1x1크기의 패치를 사용할 경우 feature map의 공간 차원을 flatten하여 각 벡터에 linear projection을 적용하면 됨.
Fine-tuning and Higher Resolution
- ViT를 pre-training한 후, 해당 모델을 downstream task에 fine-tuning하여 사용할 수 있음
- ViT를 fine-tuning 할 때, ViT의 pre-trainied prediction head를 zero-initialized feedforward layer로 대체함
- ViT에서 정보를 추출하는 transformer encoder는 그대로 사용하되, 특정 ouput을 도출하는 head에는 풀고자하는 목적에 맞게 zero-initialized feedforward layer로 대체함.
- ViT를 fine-tuning 할 때, pre-training과 동일한 패치의 크기를 사용하기 때문에 고해상도의 이미지로 fine-tuning을 하면 sequence 길이가 더 길어짐
- ViT는 가변적 길이의 패치들을 처리할 수 있지만, pre-trained position embedding은 의미가 사라지므로 pre-trained position embedding을 원본 이미지의 위치에 따라 2D interpolation하여 사용함.
- 결론: Fine tuning을 할땐, MLP head만 바꿔서 진행을 함
Experimental
- Dataset
- 모델 확장성을 탐구하기 위해 class와 이미지의 개수가 각각 다른 3개의 데이터셋을 기반으로 pre-train 됨
- ILSVRC-2012 ImageNet 데이터 세트와 1k 클래스 및 1.3M개의 이미지(이하 ImageNet이라고 함)
- 21k 클래스 및 14M 이미지를 포함하는 ImageNet-21k
- 18k 클래스 및 303M 고해상도 이미지를 포함하는 JFT
- Model Variants
- 3개의 volume에 대하여 실험을 진행하였으며, 다양한 패치크기에 대해 실험을 진행함.
- Baseline CNN은 batch normalization layer를 group normalization으로 변경하고 standardized convolutional layer를 사용하여 transfer learning에 적합한 Big Transformer (BiT)구조의 ResNet을 사용함
- 실험결과
- 본 실험에서는 14* 14 패치 크기를 사용한 ViT-Huge와 1616 패치 크기를 사용한 ViT-large의 성능을 baseline과 비교함
- JFT 데이터 셋에서 pre training한 ViT- Large / 16 모델이 모든 downstream task에 대하여 BiT-Large보다 높은 성능을 도출함
- ViT-Large / 14 모델은 ViT -Large / 16 모델보다 향상된 성능을 도출하였으며, BiT -Large 모델보다 학습 시간이 훨씬 짧음

-
- 19 - task VTAB classification suite를 아래와 같이 3개의 그룹으로 나누어 추가 실험을 진행함
- Natural : tasks like Pets, CIFAR, etc
- Specialized : medical 과 satelite imagery
- Structured: localization과 같이 geometric understading이 요구되는 task

- 본 실험에서는 pre-training 데이터 셋의 크기에 따른 fine-tuning 성능을 확인함
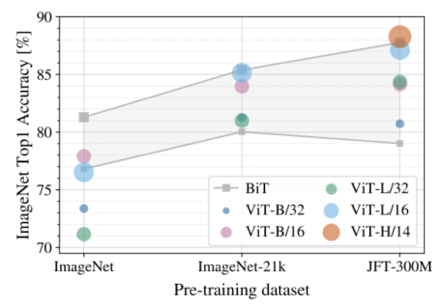
- 각 데이터셋에 대하여 pre-training한 ViT를 ImageNet에 transfer learning한 정확도를 확인한 결과, 데이터가 클수록 ViT가 BiT보다 성능이 좋고 크기가 큰 ViT모델이 효과가 있음
- JFT를 각각 다른 크기로 랜덤 샘플링한 데이터셋을 활용하여 실험을 진행한 결과, 작은 데이터셋에서 CNN의 inductive bias가 효과가 있으나 큰 데이터 셋에서는 데이터로부터 팬턴을 학습하는 것만으로도 충분함을 알 수 있음

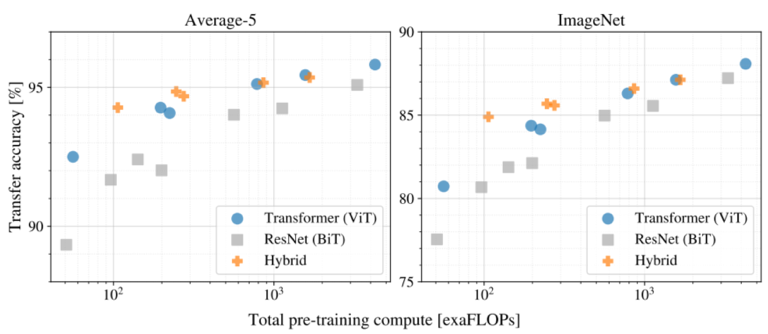
- JFT를 기반으로 pre-training cost 대비 transfer 성능을 검증하여 모델들의 scaling study를 진행함
- ViT가 성능과 cost의 trade-off에서 ResNet(BiT)보다 우세한 것을 검증함
- Cost가 증가할수록 Hybrid와 ViT의 성능과 cost의 차이가 감소함
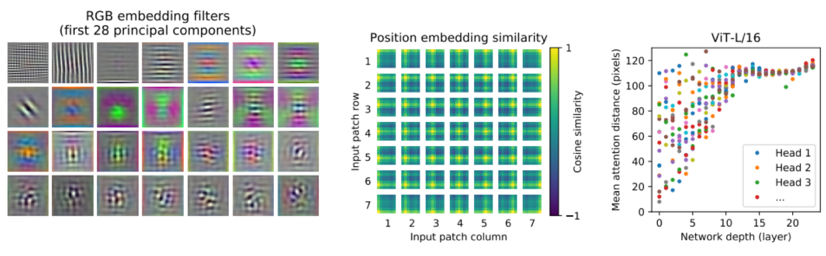
- flatten 패치를 패치 임베딩으로 변환하는 linear projection의 principal components를 분석함(왼쪽)
- 패치 간 position 임베딩의 유사도를 통해 가까운 위치에 있는 패치들의 position 임베딩이 유사한지 확인함(중앙)
- ViT의 layer별 평균 attention distance를 확인한 결과, 초반 layer에서도 attention을 통해 이미지 전체의 정보를 통합하여 사용함을 알 수 있음
Vit 연구

결론
- 우리는 이미지 인식에 트랜스포머를 직접 적용하는 방법을 탐구했다. 컴퓨터 비전에서 self-attention을 사용하는 이전 연구와 달리, 초기 패치 추출 단계와 별도로 이미지별 유도 편향을 아키텍처에 도입하지 않았습니다.
- 대신, 이미지를 패치 시퀀스로 해석하고 NLP에서 사용되는 표준 트랜스포머 인코더로 처리합니다. 이 간단하지만 확장 가능한 전략은 대규모 데이터 세트에 대한 pre-train과 결합할 때 놀라울 정도로 잘 작동합니다.
'AI > 논문분석' 카테고리의 다른 글
| exploring the limits of transfer learning with a unified text-to-text transformer - 논문 리뷰 분석 (0) | 2023.02.07 |
|---|---|
| Noisy student training -논문리뷰 분석 (0) | 2023.02.07 |
| Attention Is All You Need 논문 리뷰 분석 (0) | 2022.11.03 |
반응형
들어가기 앞서 기존 상태
- 트랜스포머 구조가 자연어 처리 task들에서 표준이 되는 동안, vision에 이를 적용한 사례는 한정되어 왔습니다. 비전 분야에서 attention은 Convolution network과 함께 적용되거나, Convolutional network의 특정 요소를 대체하기 위해 사용되었기 때문입니다.
- 해당 논문에선 이러한 CNN에 대한 의존이 필요하지 않고 순수 트랜스포머가 곧바로 이미지 패치들에 사용되고 이미지 분류에 잘 작동함을 보여줍니다.
Introduction
- NLP에서의 트랜스포머 스케일링이 성공한 것에 영감을 받아, 이 논문에서는 standard transformer를 최소한의 수정으로 직접 이미지에 적용하는 것에 대해 실험을 했습니다.
- 이를 위해, 이미지를 패치별로 쪼개고 (이미지 패치들은 NLP에서의 token과 같은 방식으로 다뤄지게 됩니다.), 이러한 패치들의 linear embeddings sequence 를 트랜스포머에 input으로 넣었습니다.
- 이 모델을 supervised 방식으로 이미지 분류에 학습을 시켜 실험하였다.
Inductive Bias
- training에서 보지 못한 데이터에 대해서도 적절한 귀납적 추론이 가능하도록 하기 위해 모델이 가지고 있는 가정들의 집합을 의미함
- 일반적으로 모델이 갖는 일반화의 오류(Generalization Problem)는 불안정하다는 것(Brittle)과 겉으로만 그럴싸 해 보이는 것(Spurious)이 있다. 모델이 주어진 데이터에 대해서 잘 일반화한 것인지, 혹은 주어진 데이터에만 잘 맞게 된 것인지 모르기 때문에 발생하는 문제이다. 이러한 문제를 해결하기 위한 것이 바로 Inductive Bias이다. Inductive Bias란, 주어지지 않은 입력의 출력을 예측하는 것이다. 즉, 일반화의 성능을 높이기 위해서 만약의 상황에 대한 추가적인 가정(Additional Assumptions)
이라고 보면 된다. - DNN의 기본적인 요소들의 inductive bias는 아래와 같음
- Fully connected: 입력 및 출력 element가 모두 연결되어 있으므로 구조적으로 특별한 relational inductive bias를 가정하지 않음
- Convolutional: CNN은 작은 크기의 kernel로 이미지를 지역적으로 보며, 동일한 kernel로 이미지 전체를 본다는 점에서 locality와 transitional invariance 특성을 가짐
- Recurrent: RNN은 입력한 데이터들이 시간적 특성을 가지고 있다고 가정하므로 sequentiality와 temporal invariance 특성을 가짐
- Transformer는 CNN및 RNN 보다 상대적으로 inductive bias가 낮음 (self attention을 기반으로 하고 있기 때문에)
- ViT에서 input이 patch단위로 들어오는 MLP(Multi-Layer Perceptron)는 locality와 translation equivariance가 있지만, CNN보다 image-specific inductive bias가 낮음
- 해당 모델에서 아래 두가지 방법을 사용하여 inductive bias의 주입을 시도함
- Patch extraction : 이미지를 자른 후 순서대로 기입
- Resolution adjustment: fine tuning을 할 때, patch의 크기를 동일하게 사용하지만, 이미지의 크기에 따라 patch 의 개수가 달라지므로, position embedding을 조정함.
개요
- 본 연구에서는 NLP에서 사용되는 standard Transformer를 이미지에 그대로 적용하여 이미지 분류에 좋은 성능을 도출한 Vision Transformer (ViT)를 제안함
- ViT는 이미지를 패치로 분할한 후, 이를 NLP의 단어로 취급하여 각 패치의 linear embedding을 순서대로 Transformer의 input으로 넣어 이미지를 분류함
- ViT를 ImageNet-1k에 학습했을 떄, 비슷한 크기의 ResNet보다 낮은 정확도를 도출하는 것을 통해 ViT가 CNN보다 inductive bias가 낮은 것을 알 수 있음
- 반면, ImageNet-21k와 JFT-300M에 pre training한 ViT를 다른 image recognition task에 transfer learning 했을 때, ViT가 SOTA 성능을 도출하는 것을 통해 large scale 학습이 낮은 inductive bias로 인한 성능 저하를 해소시키는 것을 알 수 있음
작동 방법
작동과정 5스텝
- 주어진 이미지에 대해서 이미지 x가 존재할 때, 이미지 x를 p by p크기의 정사각형 patch로 분할한 후에 patch sequence를 구축함.
- patch sequence가 구축되면, 왼쪽 위부터 오른쪽 아래로 순서대로 Trainable linear projection을 통해 분할한 각 patch를 flatten한 벡터를 D차원으로 변환한 후 , 이를 패치 임베딩으로 사용함.
- * 같은 Learnable class 임베딩과 패치 임베딩에 learnable position 임베딩을 더함
- 해당 임베딩을 Transformer encoder에 input으로 넣어 마지막 layer에서 class embedding에 대한 output인 image representation을 도출함
- 이를 MLP image representation을 input으로 넣어 이미지의 class를 분류함.
[ 이미지 인풋 ]
- 일반적인 Transformer은 토큰 임베딩에 대한 1차원의 시퀀스를 입력으로 받음
- 2차원의 이미지를 다루기 위해 논문에서는 이미지를 flatten된 2차원의 패치의 시퀀스로 변환함
- 즉, H x W x C → N x (P^2 x C) 로 변환
(H, W)는 원본 이미지의 크기, C는 채널 개수를 의미
(P, P)는 이미지 패치의 크기
N = HW/P^2 = 패치의 개수
- Transformer은 모든 레이어에서 고정된 벡터 크기 D를 사용하기 때문에 이미지 패치는 펼친 다음 D차원 벡터로 linear projection 시킴
- BERT의 [CLS]토큰과 비슷하게 임베딩 된 패치의 시퀀스에 z0 = x_class 임베딩을 추가로 붙여 넣음
- 이후 이 패치에 대해 나온 인코더 아웃풋은 이미지 representation으로 해석하여 분류에 사용
[ 위치 임베딩 ]
- 각각의 패치 임베딩에 위치 임베딩을 더하여 위치 정보를 활용할 수 있도록 함
- 학습 가능한 1차원의 임베딩을 사용
- 2차원 정보를 유지하는 위치 임베딩도 활용해 보았으나, 유의미한 성능 향상은 없었기 때문
Transformer Encoder
- ViT는 Multi-head Self Attention(MSA)와 MLP block으로 구성되어있음
- MLP는 2개의 layer를 가지며, GELU activation fuction을 사용함
- GELU activation function 이란?
- → 이것은 ReLU와 같은 또 다른 고성능 신경망 활성화이지만, 비선형성은 해당 뉴런 입력에 무작위로 ID 또는 제로 맵을 적용하는 확률적 정규화의 예상 변환을 나타낸다.
- Attention is all your need와 다르게 MLP와 multi-head attention 앞에 Layer Norm을 적용하고, 각 block뒤에는 residual connection을 적용함
Positional Embedding
- ViT에서는 아래 4가지 position 임베딩을 시도한 후, 최종적으로 가장 효과가 좋은 1D position임베딩을 ViT에서 사용함
- No positional information
- patch 임베딩만 transformer 인풋으로 사용
- 1-dimensional positional embedding
- input sequence , 패치를 3차원의 이미지가 존재할 때, 왼쪽 위부터 오른쪽 아래 순서대로 patch의 sequnce를 input으로 고려하는거.
- 2-dimensional postional embedding
- 3차원의 이미지에 대해서, 가로와 세로 축 2개로 two demesion으로 grid로 만들어서 input으로 사용
- Relative positional embeddings
- patch 들사이의 상대적인 거리를 사용한 positional embedding
- No positional information
Hybrid Architecture
- ViT는 raw image가 아닌 CNN으로 추출한 raw image의 feature map을 활용하는 hybrid architecture로도 사용할 수 있음
- Feature map은 이미 raw image의 공간적 정보를 포함하고 있으므로 hybrid architecture는 패치 크기를 1x1로 설정해도됨
- 1x1크기의 패치를 사용할 경우 feature map의 공간 차원을 flatten하여 각 벡터에 linear projection을 적용하면 됨.
Fine-tuning and Higher Resolution
- ViT를 pre-training한 후, 해당 모델을 downstream task에 fine-tuning하여 사용할 수 있음
- ViT를 fine-tuning 할 때, ViT의 pre-trainied prediction head를 zero-initialized feedforward layer로 대체함
- ViT에서 정보를 추출하는 transformer encoder는 그대로 사용하되, 특정 ouput을 도출하는 head에는 풀고자하는 목적에 맞게 zero-initialized feedforward layer로 대체함.
- ViT를 fine-tuning 할 때, pre-training과 동일한 패치의 크기를 사용하기 때문에 고해상도의 이미지로 fine-tuning을 하면 sequence 길이가 더 길어짐
- ViT는 가변적 길이의 패치들을 처리할 수 있지만, pre-trained position embedding은 의미가 사라지므로 pre-trained position embedding을 원본 이미지의 위치에 따라 2D interpolation하여 사용함.
- 결론: Fine tuning을 할땐, MLP head만 바꿔서 진행을 함
Experimental
- Dataset
- 모델 확장성을 탐구하기 위해 class와 이미지의 개수가 각각 다른 3개의 데이터셋을 기반으로 pre-train 됨
- ILSVRC-2012 ImageNet 데이터 세트와 1k 클래스 및 1.3M개의 이미지(이하 ImageNet이라고 함)
- 21k 클래스 및 14M 이미지를 포함하는 ImageNet-21k
- 18k 클래스 및 303M 고해상도 이미지를 포함하는 JFT
- Model Variants
- 3개의 volume에 대하여 실험을 진행하였으며, 다양한 패치크기에 대해 실험을 진행함.
- Baseline CNN은 batch normalization layer를 group normalization으로 변경하고 standardized convolutional layer를 사용하여 transfer learning에 적합한 Big Transformer (BiT)구조의 ResNet을 사용함
- 실험결과
- 본 실험에서는 14* 14 패치 크기를 사용한 ViT-Huge와 1616 패치 크기를 사용한 ViT-large의 성능을 baseline과 비교함
- JFT 데이터 셋에서 pre training한 ViT- Large / 16 모델이 모든 downstream task에 대하여 BiT-Large보다 높은 성능을 도출함
- ViT-Large / 14 모델은 ViT -Large / 16 모델보다 향상된 성능을 도출하였으며, BiT -Large 모델보다 학습 시간이 훨씬 짧음
-
- 19 - task VTAB classification suite를 아래와 같이 3개의 그룹으로 나누어 추가 실험을 진행함
- Natural : tasks like Pets, CIFAR, etc
- Specialized : medical 과 satelite imagery
- Structured: localization과 같이 geometric understading이 요구되는 task
- 본 실험에서는 pre-training 데이터 셋의 크기에 따른 fine-tuning 성능을 확인함
- 각 데이터셋에 대하여 pre-training한 ViT를 ImageNet에 transfer learning한 정확도를 확인한 결과, 데이터가 클수록 ViT가 BiT보다 성능이 좋고 크기가 큰 ViT모델이 효과가 있음
- JFT를 각각 다른 크기로 랜덤 샘플링한 데이터셋을 활용하여 실험을 진행한 결과, 작은 데이터셋에서 CNN의 inductive bias가 효과가 있으나 큰 데이터 셋에서는 데이터로부터 팬턴을 학습하는 것만으로도 충분함을 알 수 있음
- JFT를 기반으로 pre-training cost 대비 transfer 성능을 검증하여 모델들의 scaling study를 진행함
- ViT가 성능과 cost의 trade-off에서 ResNet(BiT)보다 우세한 것을 검증함
- Cost가 증가할수록 Hybrid와 ViT의 성능과 cost의 차이가 감소함
- flatten 패치를 패치 임베딩으로 변환하는 linear projection의 principal components를 분석함(왼쪽)
- 패치 간 position 임베딩의 유사도를 통해 가까운 위치에 있는 패치들의 position 임베딩이 유사한지 확인함(중앙)
- ViT의 layer별 평균 attention distance를 확인한 결과, 초반 layer에서도 attention을 통해 이미지 전체의 정보를 통합하여 사용함을 알 수 있음
Vit 연구
결론
- 우리는 이미지 인식에 트랜스포머를 직접 적용하는 방법을 탐구했다. 컴퓨터 비전에서 self-attention을 사용하는 이전 연구와 달리, 초기 패치 추출 단계와 별도로 이미지별 유도 편향을 아키텍처에 도입하지 않았습니다.
- 대신, 이미지를 패치 시퀀스로 해석하고 NLP에서 사용되는 표준 트랜스포머 인코더로 처리합니다. 이 간단하지만 확장 가능한 전략은 대규모 데이터 세트에 대한 pre-train과 결합할 때 놀라울 정도로 잘 작동합니다.
'AI > 논문분석' 카테고리의 다른 글
| exploring the limits of transfer learning with a unified text-to-text transformer - 논문 리뷰 분석 (0) | 2023.02.07 |
|---|---|
| Noisy student training -논문리뷰 분석 (0) | 2023.02.07 |
| Attention Is All You Need 논문 리뷰 분석 (0) | 2022.11.03 |