
반응형
스파크 SQL은 관계형 처리와 스파크의 함수형 프로그래밍 API를 통합하는 아파치 스파크의 기본 구성 요소입니다.
스파크 SQL을 사용하면 스파크 프로그래머는 더 빠른 성능 및 관계형 프로그래밍 이점을 활용할 수 있을 뿐만 아니라 복잡한 분석 라이브러리(ex.ML)을 호출 할 수 있습니다.
사용자 정의함수
Apache Spark는 대량의 내장 함수를 제공하기도 하지만, 데이터 엔지니어와 과학자도 자신의 기능을 정의할 수 있는 유연성 또한 제공합니다. 이를 사용자 정의함수(user-defined function,UDF)라고 합니다.
Spark SQL UDF
사용자만의 PySpark UDF를 생성하는 이점은 사용자도 스파크 SQL 안에서 이를 사용할 수 있습니다. 이를 통해 내부를 이해하지 않고도 스파크 SQL에서 예측 결과를 바로 쿼리할 숭 있으며 과학자는 해당 모델을 UDF로 생성할 수 있습니다.
다음은 UDF 예시 입니다.
# from pyspark.sql.types import DataType
from pyspark.sql import SparkSession
spark = (SparkSession
.builder
.appName("SpakrSQLExampleApp")
.enableHiveSupport() # Hive 지원 활성화
.getOrCreate())
def cubed(s): # 큐브 함수 생성
return s*s*s
spark.udf.register("cubed",cubed) # UDF로 등록
spark.range(1,9).createOrReplaceTempView("udf_test") # 임시 뷰
spark.sql("Select id,cubed(id) AS id_cubed FROM udf_test").show()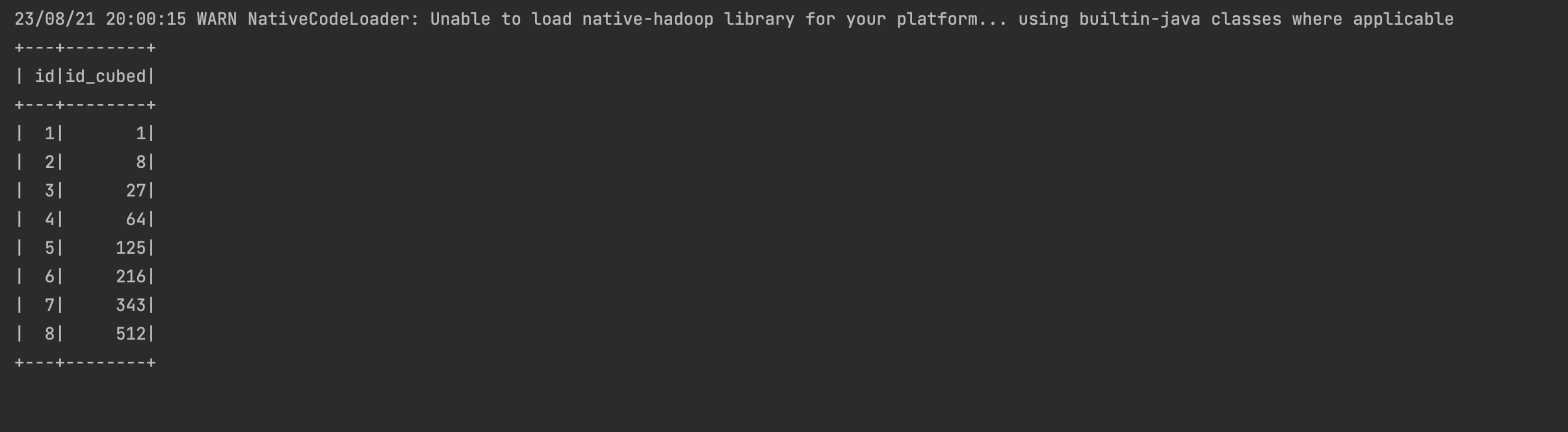
해당 UDF는 세션별로 작동하며 기본 메타 스토어에서는 유지되지 않습니다.
판다스 UDF로 파이스파크 UDF 속도 향상 및 배포
기본 PySpark UDF 사용과 관련하여 기존의 일반적인 문제 중 하나는 스칼라 UDF보다 성능이 느리다는 점이였습니다. 해당 이유는 UDF가 JVM과 파이썬 사이의 데이터 이동을 필요로 해서 비용이 많이 들었기 때문입니다. 해당 문제를 해결하기 위해 Pandas UDF가 도입됐습니다. pandas_udf 키워드를 데코레이터로 사용하여 pandas UDF를 정의하거나 함수 자체를 래핑할 수 있습니다.
import pandas as pd
from pyspark.sql.functions import col,pandas_udf
from pyspark.sql import SparkSession
spark = (SparkSession
.builder
.appName("SpakrSQLExampleApp")
.enableHiveSupport() # Hive 지원 활성화
.getOrCreate())
def cubed(a:pd.Series) -> pd.Series:
return a*a*a
cubed_udf = pandas_udf(cubed)
df = spark.range(1,4)
df.select("id",cubed_udf(col("id"))).show()
'Apache > Apache Spark' 카테고리의 다른 글
| 스파크 애플리케이션의 최적화 및 튜닝 (2) | 2023.09.07 |
|---|---|
| SQL 테이블과 뷰 (0) | 2023.08.20 |
| Spark SQL과 데이터 프레임 (0) | 2023.08.20 |
| Spark DDL을 사용하여 dataframe 생성하기 (0) | 2023.08.04 |
| Spark의 구조 확립 (0) | 2023.08.04 |