
반응형
스파크 SQL 특징
스파크 SQL은 다음과 같은 특징을 갖습니다.
- 상위 수준의 정형화 API가 엔진으로 제공된다.
- 다양한 정형 데이터를 읽거나 쓸수 있다.(ex) JSON, csv, Parquet)
- BI의 데이터 소스나 MySQL 및 PostgreSQL과 같은 RDBMS의 데이터를 JDBC/ODBC 커넥터를 사용하여 쿼리할 수 있습니다.
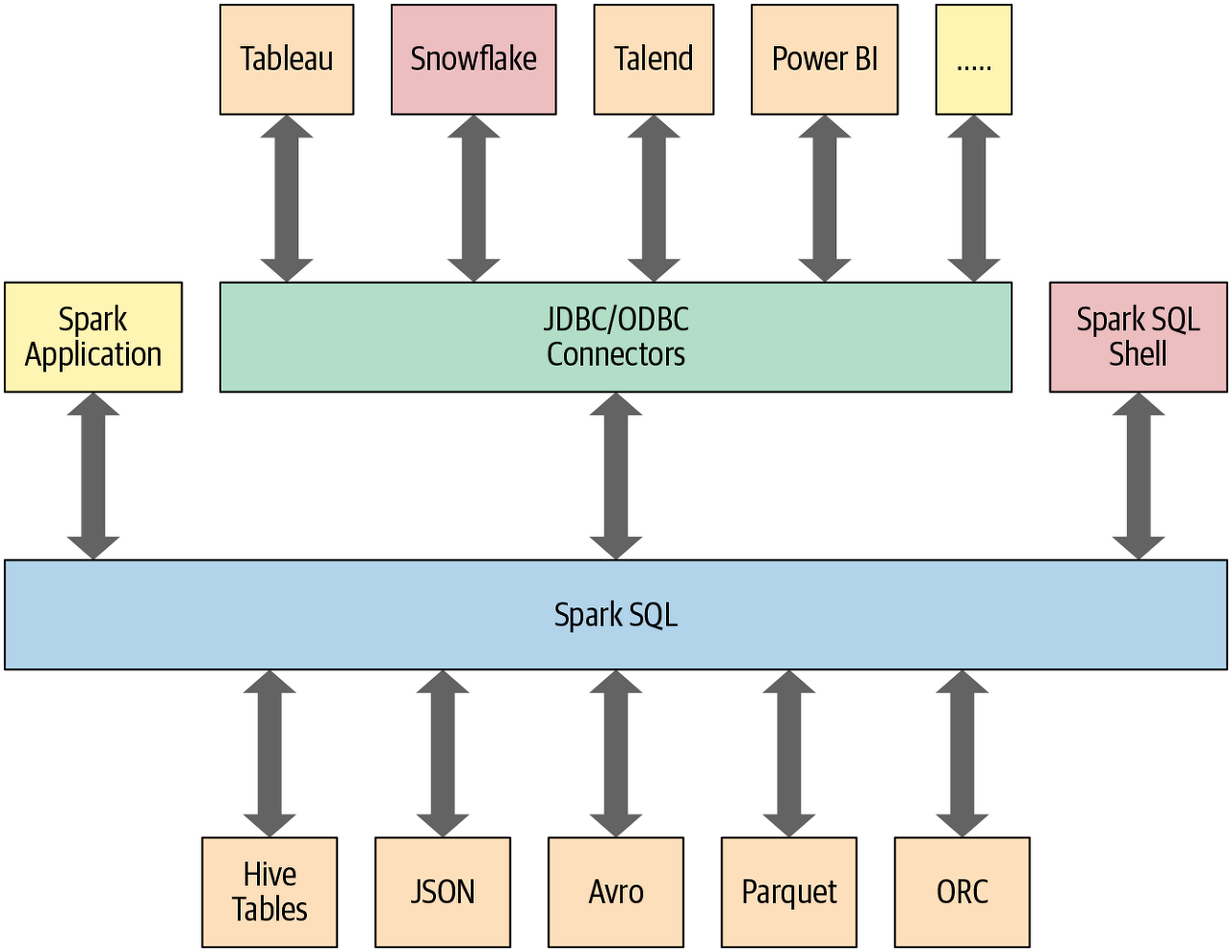
스파크의 기능에 접근할 수 있는 SparkSession을 사용하면 쉽게 클래스를 가져오고 코드에서 인스턴스를 생성할 수 있습니다.
이에따라 SQL 쿼리를 실행하기 위해선 spark라고 선언된 SparkSession 인스턴스에서 spark.sql("SELECT * FROM myTableName")과 같은 sql() 함수를 사용합니다.
from pyspark.sql import SparkSession
# SparkSession 생성
spark = (SparkSession
.builder
.appName("SpakrSQLExampleApp")
.getOrCreate())
# 데이터 셋 경로
csv_file = "./departuredelays.csv"
# 읽고 임시뷰를 생성
# 스키마 추론( 더 큰 파일의 경우 스키라를 지정)
df = (spark.read.format("csv")
.option("inferSchema","true")
.option("header","true")
.load(csv_file))
df.createOrReplaceTempView("us_delay_flights_tbl")
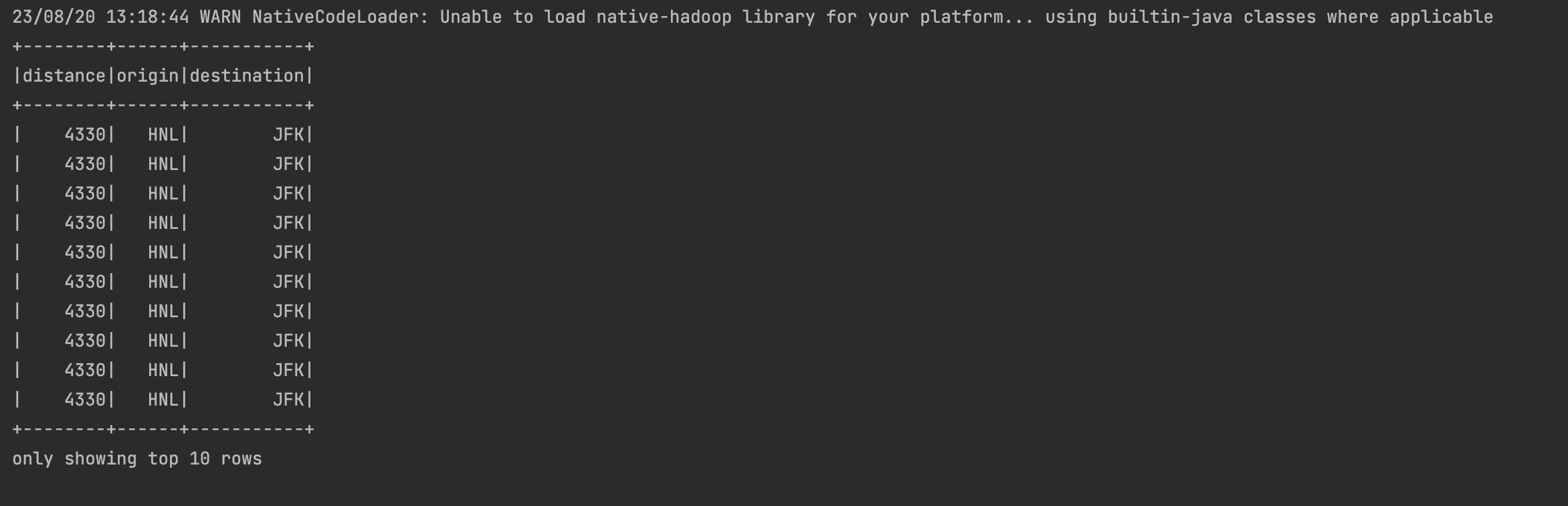
spark.sql("""SELECT distance,origin,destination
FROM us_delay_flights_tbl WHERE distance > 1000
ORDER BY distance DESC""").show(10)해당 코드를 통해 csv 파일로 제공된 데이터를 스키마를 사용하여 데이터세트를 임시 뷰로 읽어서 사용할 수 있습니다.
'Apache > Apache Spark' 카테고리의 다른 글
| Spark SQL과 아파치 하이브 (5) | 2023.08.21 |
|---|---|
| SQL 테이블과 뷰 (0) | 2023.08.20 |
| Spark DDL을 사용하여 dataframe 생성하기 (0) | 2023.08.04 |
| Spark의 구조 확립 (0) | 2023.08.04 |
| 스파크 애플리케이션 개념의 이해 (0) | 2023.07.31 |
반응형
스파크 SQL 특징
스파크 SQL은 다음과 같은 특징을 갖습니다.
- 상위 수준의 정형화 API가 엔진으로 제공된다.
- 다양한 정형 데이터를 읽거나 쓸수 있다.(ex) JSON, csv, Parquet)
- BI의 데이터 소스나 MySQL 및 PostgreSQL과 같은 RDBMS의 데이터를 JDBC/ODBC 커넥터를 사용하여 쿼리할 수 있습니다.
스파크의 기능에 접근할 수 있는 SparkSession을 사용하면 쉽게 클래스를 가져오고 코드에서 인스턴스를 생성할 수 있습니다.
이에따라 SQL 쿼리를 실행하기 위해선 spark라고 선언된 SparkSession 인스턴스에서 spark.sql("SELECT * FROM myTableName")과 같은 sql() 함수를 사용합니다.
from pyspark.sql import SparkSession
# SparkSession 생성
spark = (SparkSession
.builder
.appName("SpakrSQLExampleApp")
.getOrCreate())
# 데이터 셋 경로
csv_file = "./departuredelays.csv"
# 읽고 임시뷰를 생성
# 스키마 추론( 더 큰 파일의 경우 스키라를 지정)
df = (spark.read.format("csv")
.option("inferSchema","true")
.option("header","true")
.load(csv_file))
df.createOrReplaceTempView("us_delay_flights_tbl")
spark.sql("""SELECT distance,origin,destination
FROM us_delay_flights_tbl WHERE distance > 1000
ORDER BY distance DESC""").show(10)해당 코드를 통해 csv 파일로 제공된 데이터를 스키마를 사용하여 데이터세트를 임시 뷰로 읽어서 사용할 수 있습니다.
'Apache > Apache Spark' 카테고리의 다른 글
| Spark SQL과 아파치 하이브 (5) | 2023.08.21 |
|---|---|
| SQL 테이블과 뷰 (0) | 2023.08.20 |
| Spark DDL을 사용하여 dataframe 생성하기 (0) | 2023.08.04 |
| Spark의 구조 확립 (0) | 2023.08.04 |
| 스파크 애플리케이션 개념의 이해 (0) | 2023.07.31 |