
대규모 워크로드를 위한 스파크 규모 확장
대규모 스파크 워크로드는 배치 잡인 경우가 종종 있으며, 시간적으로 파일을 실행하는 식입니다. 이때 자원부족이나 점진적인 성능 저하에 의한 작업 실패를 피하기 위해 사용해볼 수 있는 여러 스파크 설정들이 존재합니다. 해당 설정들은 스파크 드라이버, 이그제큐터, 이그제큐터에서 실행되는 셔플 서비스 등 세가지 스파크 컴포넌트에 영향을 미칩니다.
스파크 드라이버는 클러스터 매니저와 함께 클러스터에 이그제큐터들을 띄우고 그 위에서 돌아갈 수 있는 스파크 태스크들을 스케줄링 하는 역할을 합니다.
기존 정적으로 자원량을 제한하려면 spark-submit에 명령 행 인자로 자원량을 지정할 수 있었습니다. 하지만 이는 워크로드보다 더 방대한 작업으로 인해 드라이버에 나중에 테스크들이 기다리는 상황(병목현상)이 온다면 추가적인 자원들을 더 할당 할 수 없게됩니다.
이러한 문제를 피하기 위해 스파크의 동적 자원 할당 설정을 사용한다면 스파크는 드라이버는 유동적으로 워크로드의 용량에 맞춰 컴퓨팅 자원을 더 할당하거나 줄이도록 요청 할 수 있게됩니다. 즉, 워크로드가 동적인 자원을 바탕으로 작동하는 시나리오라면 동적 할당을 사용하는 것이 도움이 될 수 있습니다.
spark.dynamicAllocation.enabled 를 true로 바꾼 예시를 보여드리겠습니다.
spark.dynamicAllocation.enabled true
spark.dynamicAllocation.minExecutors 2
spark.dynamicAllocation.schedulerBacklogTimeout 1m
spark.dynamicAllocation.maxExecutors 20
spark.dynamicAllocation.executorIdleTimeout 2min해당 예시를 바탕으로 설명을 해드리겠습니다. 기본적으로 스파크 동적할당은 False로 되어있습니다.
해당 값을 true로 설정하게 되면 스파크 드라이버는 클러스터 매니저가 최소 이그제큐터 개수인 두개로 시작하도록 요청합니다.(spark.dynamicAllocation.minExecutors). 태스크 큐 백로그가 늘어나면 매번 백로그 타임 아웃시간이 될 때마다 새로운 이그제큐터를 요청하게 됩니다.
이때 1분이상 스케줄링되지 않은 태스크들이 기다리고 있으면 언제든 드라이버는 백로깅 된 태스크들이 실행 될 새로운 이그제큐터가 실행되도록 요청하며 20개까지 가능하게 됩니다.
이후 이그제큐터가 태스크를 전부 다 완료한 후 2분동안 놀고 있으면 드라이버는 이그제큐터를 종료합니다.
스파크 이그제큐터의 메모리와 셔플 서비스 설정
단순히 동적 자원 할당을 활성화 하는 것만으로는 충분하지 않습니다. 이그제큐터들이 메모리 부족에 시달리거나 JVM 가비지 컬렉션으로 문제를 격지 않게 하려면 이그제큐터 메모리가 어떤 식으로 구성 되고 스파크가 어덯게 사용하는지도 알아둬야 합니다.
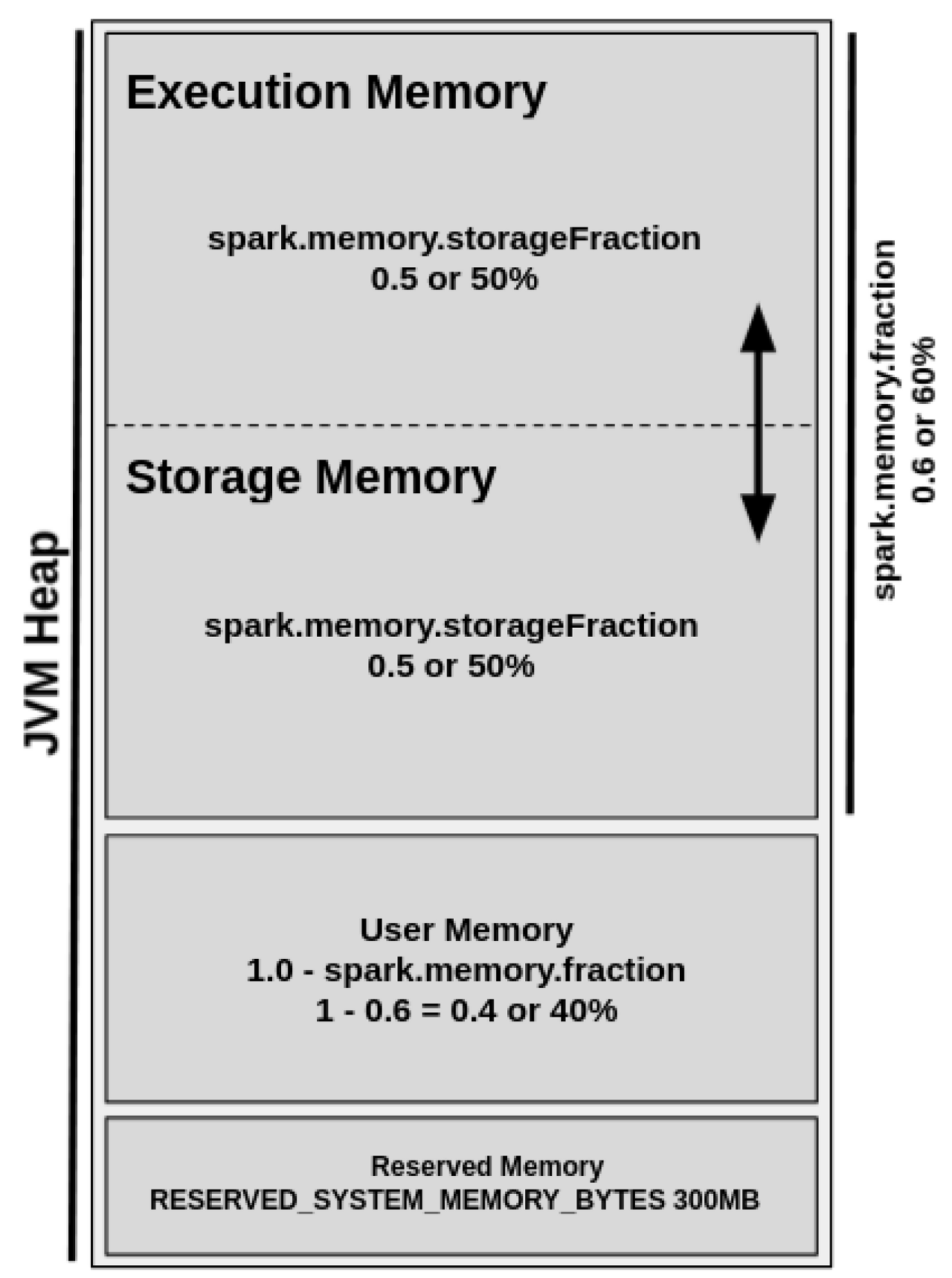
이그제큐터에서 사용 가능한 메모리 양은 spark.executor.memory에 의해 제어됩니다. 해당 메모리는 실행 메모리, 저장 메모리, 예비 메모리로 나눠집니다. 보통 예비 메모리에 300MB를 할당 한 후, 나머지 실행 메모리에서 60%, 저장 메모리에 40%가 할당 됩니다.
해당 spark.executor.memory의 비율을 베이스 라인 삼아 원하는 수치로 조정할 수 있습니다.
| 설정 이름 | 기본값, 추천값, 설명 |
|---|---|
| spark.driver.memory | 기본값은 1GB입니다. 이는 스파크 드라이버가 이그제큐터들에게 데이터를 받기 위해 할당되는 메모리 양입니다. 이 값은 collect() 같은 함수로 드라이버가 많은 데이터를 받아 올 때 메모리가 부족할 수 있으므로 조정하도록 합니다. |
| spark.shuffle.file.buffer | 기본값은 32KB입니다. 보편적으론 1MB를 사용합니다.이는 스파크가 맵 결과를 디스크에 쓰기 전에 버퍼링을 더 많이 할 수 있게 합니다. |
| spark.file.transferTo | 기본값은 true입니다. 이를 false로 바꾸면 스파크가 디스크에 쓰기 전에 파일 버퍼를 사용하도록 하며 이는 I/O 횟수를 줄일 수 있습니다. |
| spark.shuffle.unsafe.file.output.buffer | 기본값은 32KB입니다. 셔플 작업 중 파일을 병합할 때 가능한 버퍼의 양을 조절합니다. |
| spark.io.compression.lz4.blockSize | 기본값은 32KB입니다. 보편적으로 512KB를 사용합니다. 이는 압축하는 블록 단위를 크게 함으로 셔플 파일의 크기를 줄일 수 있습니다. |
| spark.shuffle.service.index.cache.size | 기본값은 100m입니다. 캐시되는 엔트리들 개수는 지정된 메모리 용량에 따라 제한됩니다. |
| spark.shuffle.registration.timeout | 기본값은 5000ms입니다. 120000ms로 올리는 것이 좋습니다. 이는 셔플 서비스 등록을 위한 최대 대기 시간입니다. |
| spark.shuffle.registration.maxAttempts | 기본값은 3입니다. 셔플 서비스 등록 실패시 재시도 횟수입니다. |
스파크 병렬성 최대화
스파크의 유용성의 많은 부분들은 여러 태스크를 동시에 대규모로 실행시킬 수 있는 능력입니다.
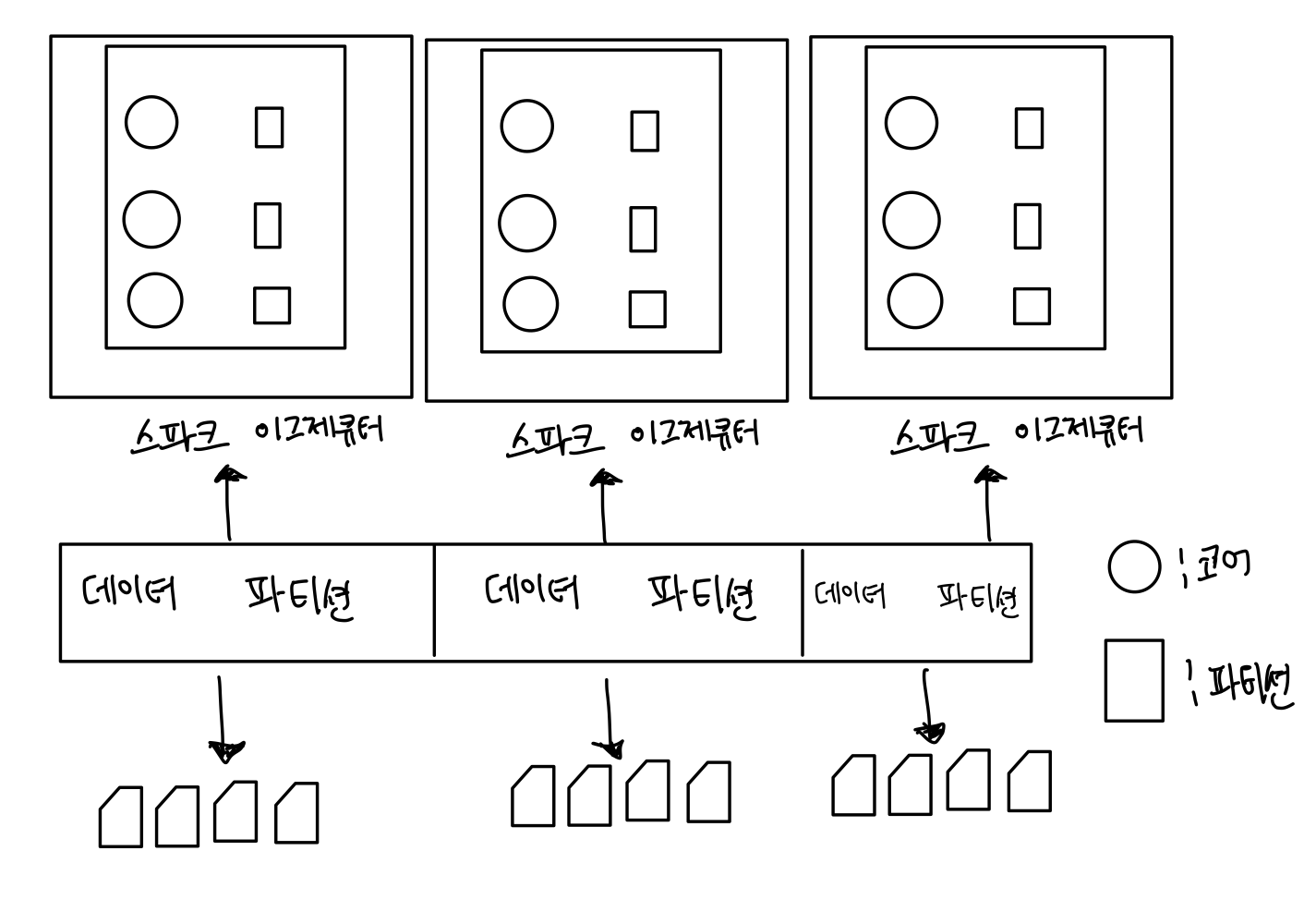
데이터 관리 용어에서 파티션이란 데이터를 관리 가능하고 쉽게 읽어 들일 수 있도록 디스크에 연속된 위치에 조각이나 블록들의 모음으로 나눠서 저장하는 방법이니다. 해당 데이터 모음들은 병렬적으로 또 독릭접으로 읽어서 처리가 가능하며 필요하면 하나의 프로세스 안에서 멀티 스레딩으로 처리도 가능합니다.
대용량 워크로드를 위한 스파크 잡은 여러 스테이지를 거치게 되고 각 스테이지에서 많은 태스크를 처리하게 됩니다. 스파크는 각 코어에서 태스크를 할당하고 각 태스크에 또 스레드를 스케줄링 하고 각 테스크는 개별 파티션을 처리하게 됩니다.
즉, 파티션이 가장 기본적인 병렬성의 한 단위로 생각할 수 있고, 하나의 코에서 돌아가는 하나의 스레드는 하나의 파티션을 처리할 수 있게 됩니다.
'Apache > Apache Spark' 카테고리의 다른 글
| Spark SQL과 아파치 하이브 (5) | 2023.08.21 |
|---|---|
| SQL 테이블과 뷰 (0) | 2023.08.20 |
| Spark SQL과 데이터 프레임 (0) | 2023.08.20 |
| Spark DDL을 사용하여 dataframe 생성하기 (0) | 2023.08.04 |
| Spark의 구조 확립 (0) | 2023.08.04 |