
반응형
해당 내용은 학부과정 중 배운 내용으로 배웠던 것을 정리하고자 작성하였습니다.
Bloom filter 개념
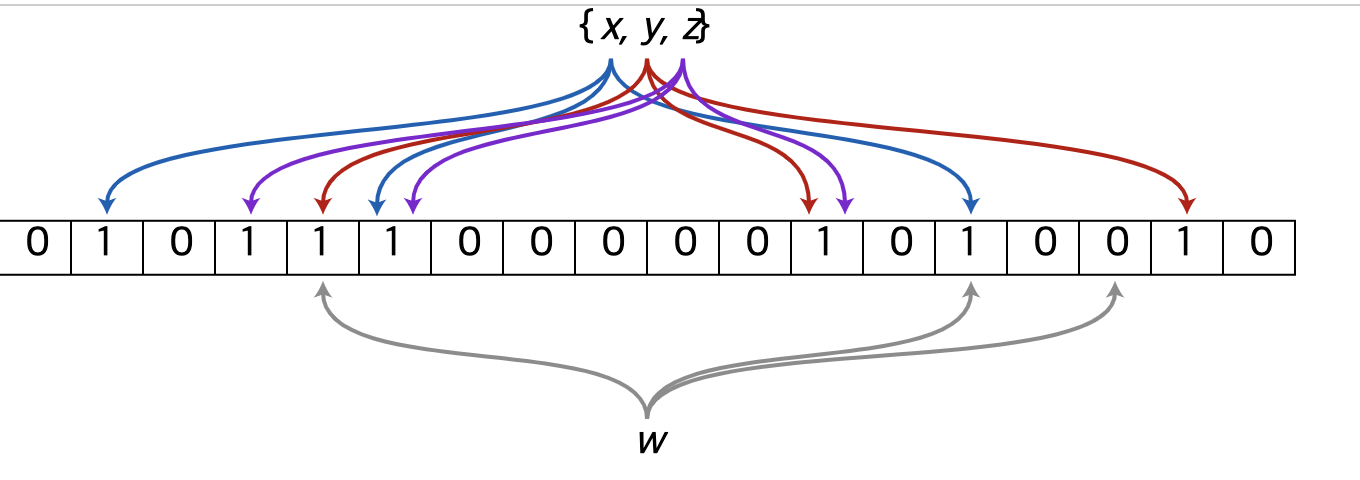
- Bloom filter란 원소가 집합에 속하는지 여부를 검사하는데 사용되는 확률적 자료 구조입니다.
- Bloom filter는 원소의 전체 데이터를 저장하지 않고, Hash 함수를 통해 원소의 특징 값들만 뽑아서 그냥 비트 배열에 반영시킵니다. 따라서 정확도는 떨어지게 되지만 메모리 사이즈를 매우 절약 할 수 있게 됩니다.
- Bloom filter에 의해 어떤 원소가 집합에 속한다고 판단된 경우 실제로는 원소가 집합에 속하지 않는 false positive가 발생하는 것이 가능하지만, 반대로 원소가 집합에 속하지 않는 것으로 판단되었는데 실제로는 원소가 집합에 속하는 false negative는 절대로 발생하지 않는다는 특성이 있습니다. 또한 집합에 원소를 추가하는 것은 가능하나, 집합에서 원소를 삭제하는 것은 불가능합니다. 집합내 원소의 숫자가 증가할수록 긍정 오류 발생 확률도 증가합니다.
bit 벡터는 기본 데이터 구조로 구현됩니다.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|
해당 테이블의 각 비어있는 cell은 bit와 그 아래의 숫자를 index로 지정합니다. bloom filter에 요소를 추가하려면 몇 번의 hash작업을 거친 후 , 해당 hash 위치 또는 index에 있는 bit 벡터를 1로 설정합니다.
S의 집합 개수는 m개, hash 함수는 k개가 있다면, n*k의 인덱스가 생성됩니다.
이때 False positive가 일어날 확률은 해당 수식으로 표현 할 수 있습니다.

이때 False positive가 최소가 되려면 전체 원소의 개수 m, 비트배열 V의 크기인 n, 해쉬 함수개수 k, 이 3개의 값중 2개의 값을 알면 False positive가 최소가 되도록 다른 변수의 값을 구할수 있습니다.
즉, 아래 수식이 성립하면 False positive는 최소 값을 가집니다.
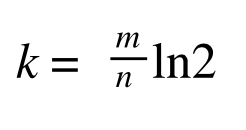
이때 비트 배열의 크기가 클수록 당연히 False positive의 값은 작아지면서 Bloom filter의 성능은 향상됩니다. 하지만 비트배열의 크기가 메모리가 관리할 수 있는 범위를 벗어나게 되면 메모리 사용량이 과부하가 되어 적절히 조정해야합니다.
마무리로 false positive를 구할 수 있는 해외 사이트를 링크로 남겨드리며 글을 마치겠습니다.
- 추천 사이트
'Big data > Data mining' 카테고리의 다른 글
| Selenium 으로 쿠팡 리뷰데이터 Crawling 해보기 (0) | 2022.10.10 |
|---|---|
| Apriori Algorithm(연관규칙분석) 이란? (0) | 2022.08.10 |
| [Python] split-folders 폴더 나누기 (0) | 2022.07.13 |