

월마트의 맥주와 기저귀
혹시 그런 글을 본적이 있으신가요? 결혼한 성인 남성이 마트에서 귀저귀를 사면 높은 확률로 맥주를 사게 된다는 말.
미국 대형마트 중 하나인 월마트는 고객들의 소비 패턴을 분석한 후 결과를 보니 맥주와 귀저귀는 서로 연관성도 없고 곂치는 품목도 아닌데두 제품이 같이 많이 팔린다는 것을 발견했습니다. 이처럼 빅데이터 속 데이터들의 연관규칙을 분석을 하는 것이 기업에 큰 이익이 될 경우가 많은데요 대표적인 연관분석 알고리즘인 Apriori Algorithm에 대하여 한번 알아보도록 하겠습니다.
Apriori Algorithm이란 무엇인가?
Apriori 알고리즘이란 어떤 두 아이템 집합이 자주 발생하는가에 대하여 일련의 규칙들을 생성하는 알고리즘입니다. 컨텐츠를 기반한 항목 추천의 기본이 되는 알고리즘 중 하나입니다. 해당 알고리즘을 실행하기 위해서는 탐석을 위한 Transaction Data와 최소 지지도(Minimum Support)가 필요합니다. 최소 지지도를 기반으로 Itemsets들을 걸러줍니다.
Apriori Algorithm 실행 과정
1. Minimum Support를 설정하고, Dataset을 탐색합니다. 이때 해당 데이터셋을 집합으로 변환해야 합니다 이를 통해 얼마나 빈번하게 등장하는 집합인지 구합니다. 이 후 , 집합의 Support값은 Minimum Support보다 커야합니다.
2. 위에서 구한 집합을 기반으로 다시 한번 빈번항목집합을 생성합니다. 이 때, 생성한 후보들 중에 위에 있는 빈번항목집합에 없는 Item이 있으면, 반드시 제외합니다.
집합을 Minimum Support 기준으로 없애기 때문에 분석 초반에는 이러한 항목들이 생성될 확률이 거의 없지만, 반복 횟수가 커질수록 이런 경우가 많아지기 때문에 꼭 제외해줘야 합니다.
3. 더 이상 집합이 만들어지지 않거나, 내가 원하는 횟수만큼 반복할 때까지 이 과정을 반복합니다.
추가적으로 용어들에 대하여 설명해드리도록 하겠습니다.
- support(지지도)
전체 거래에서 특정 물품 A와 B가 동시에 거래되는 비중
해당 규칙이 얼마나 의미있는지 보여줌.
지지도 = P(A∩B)
:A와 B가 동시에 일어난 횟수 / 전체 거래 횟수
- confiddence(신뢰도)
A를 포함하는 거래 중 A와 B가 동시에 거래되는 비중
신뢰도 = P(A∩B) / P(A)
:A와 B가 동시에 일어난 횟수 / A가 일어난 횟수
- lift(향상도)
A라는 상품에서 신뢰도가 동일한 상품 B와 C가 존재할 때, 어떤 상품을 더 추천해야 좋을지 판단.
A와 B가 동시에 거래된 비중을 A와 B가 서로 독립된 사건일 때 동시에 거래된 비중으로 나눈 값
향상도 = P(A∩B) / P(A)*P(B) = P (B|A) / P (B)
: A와 B가 동시에 일어난 횟수 / A, B가 독립된 사건일 때 A,B가 동시에 일어날 확률
예시:
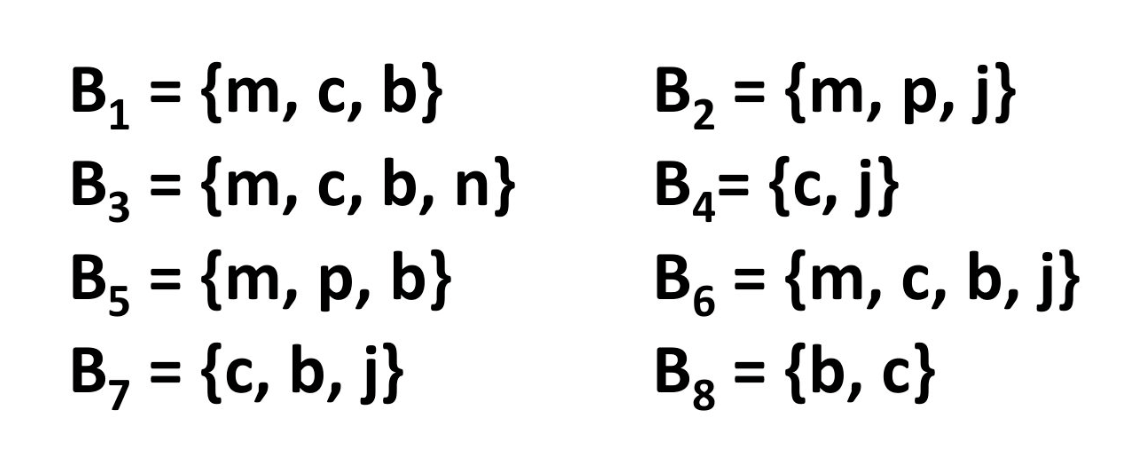
이때 threshold s 가 3이라 가정하고, confidence c 가 0.75라 가정합니다.
이후 association rule을 적용하여 confidence를 구해보면
b -> m : c = 4/6- b -> c : c = 5/6
- m -> b : c = 4/5
b,c -> m : c = 3/5- b,m -> c : c = 3/4
b -> c,m :c = 3/6- .....
등이 나오게 됩니다. 이후 confidence c보다 낮은 걸 제외하면 됩니다.
Apriori Algorithm 기본 설정
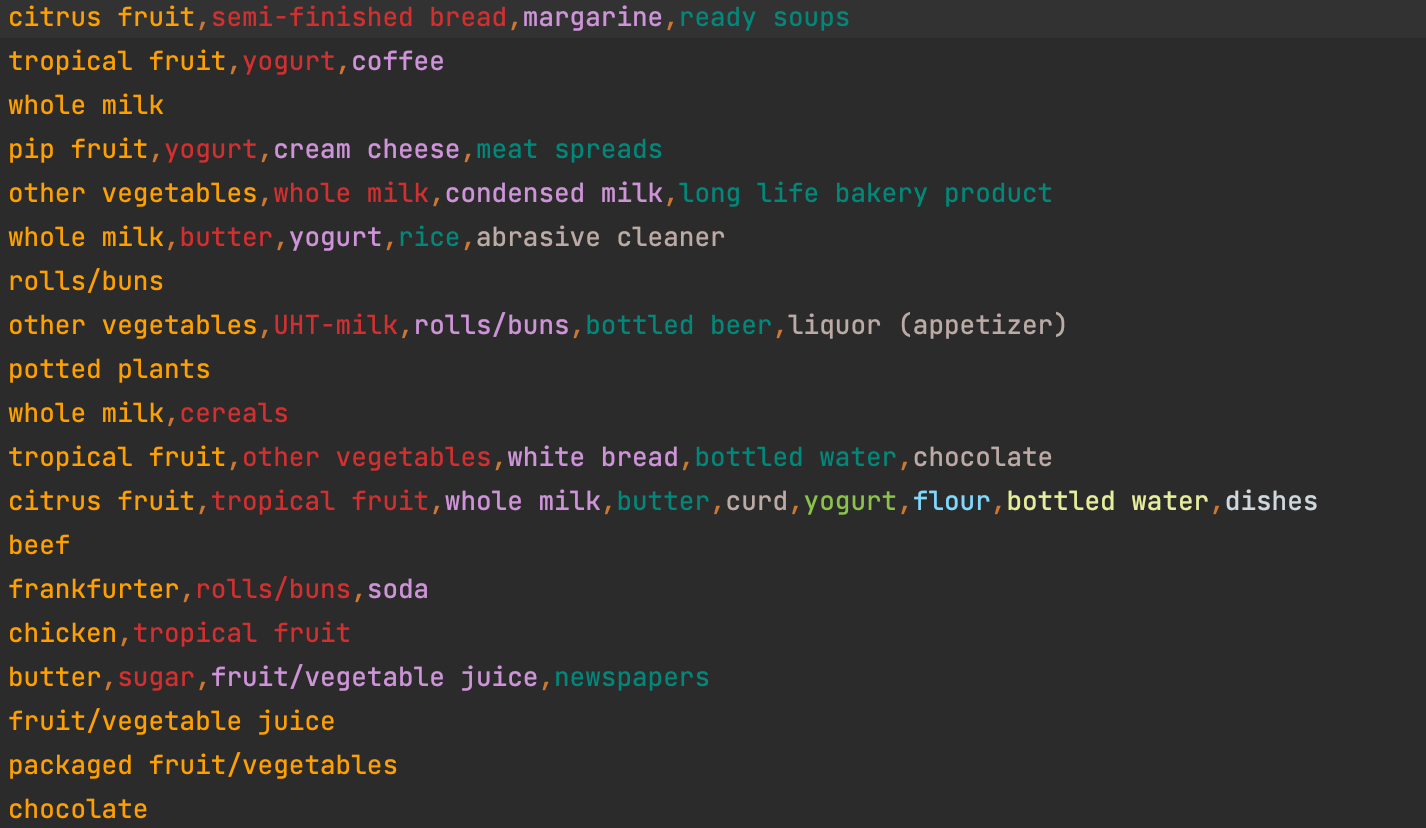
기본적으로 DBMS에서 데이터를 추출하면
1. cirtrus fruit
1. semi - finished bread
1 . margarine
1. ready soups
2. tropical fruit
2. yogurt
2. coffee
3. whole milk
이런식으로 되어있다. 해당 데이터를 아래의 데이터 구조로 변환해야합니다.
즉 data = [[a,b,c],[a,d,f],[z]]
해당 데이터를 변환하는 내용은 varkiry05 님의 블로그에 상세하게 작성되어있으니 참고하면 좋을 듯 싶습니다.
Apriori Algorithm 코드 구현
import itertools
from itertools import combinations
def filter(candidates,k,s):
itemsets_cnt_k = {}
with open ("groceries.csv","r") as f:
for line in f:
basket = line.strip().split(',')
for comb in combinations(basket,k):
comb = frozenset(comb)
if comb in candidates:
if comb not in itemsets_cnt_k:
itemsets_cnt_k[comb] = 0
itemsets_cnt_k[comb] +=1
freq_itemsets = set(itemset for itemset, cnt in itemsets_cnt_k.items() if cnt >= s)
return freq_itemsets
def make_candidate(freq_itemsets,k):
candidates = set()
for itemset1 in freq_itemsets:
for itemset2 in freq_itemsets:
union = itemset1 | itemset2
if len(union) == k:
for item in union:
if union - {item} not in freq_itemsets:
break
else:
candidates.add(union)
return candidates
def association_rule(freq_itemsets_all,cnt,candidate_all):
while(True):
for i in freq_itemsets_all:
a = frozenset(list(itertools.combinations(i,cnt)))
if len(a) == 1:
continue
elif (len(a)) != 1:
a = a - frozenset(i)
for k in a: # 부분집합
k = frozenset(k)
support_i = 0
support_j = 0
for j in candidate_all:
if k == j.intersection(k):
support_i +=1
if i == i.intersection(j):
support_j +=1
confidence = support_j/ support_i
print(f'{set(k)} -> {set(i)} = confidence : {confidence}, support_i = {support_i}, support_j = {support_j}')
else:
cnt+=1
# item 개수 구하기
item_cnt = {}
s = 100
with open ("groceries.csv","r") as f:
for line in f:
basket = line.strip().split(',')
for item in basket:
if item not in item_cnt:
item_cnt[item] = 0
item_cnt[item] +=1
# L1
freq_itemsets = set(frozenset([item]) for item, cnt in item_cnt.items() if cnt >= s)
freq_itemsets_all = freq_itemsets.copy()
candidates_all = set(make_candidate(freq_itemsets,2))
k = 2
while len(freq_itemsets) > 0:
candidates = make_candidate(freq_itemsets,k)
candidates_all |= set(candidates)
freq_itemsets = filter(candidates,k,s)
freq_itemsets_all |= freq_itemsets
print(k,len(candidates),len(freq_itemsets))
k += 1
association_rule(list(freq_itemsets_all),1,candidates_all)
for fi in freq_itemsets_all:
print(set(fi))
# print(candidates_all)이상으로 포스팅을 마치겠습니다 . 감사합니다.
참고 및 출처:
- https://lemontia.tistory.com/903
- https://velog.io/@sossont/A-priori-Algorithm%EC%9D%84-%EC%9D%B4%EC%9A%A9%ED%95%9C-%EC%83%81%EA%B4%80%EA%B4%80%EA%B3%84-%EB%B6%84%EC%84%9D
- https://ratsgo.github.io/machine%20learning/2017/04/08/apriori
'Big data > Data mining' 카테고리의 다른 글
| Selenium 으로 쿠팡 리뷰데이터 Crawling 해보기 (0) | 2022.10.10 |
|---|---|
| [Python] split-folders 폴더 나누기 (0) | 2022.07.13 |
| Bloom filter (블룸 필터)란? (0) | 2022.06.30 |