
캡스톤디자인 회고 및 프로젝트 정리 3장
캡스톤디자인 회고 및 프로젝트 정리 2장 캡스톤디자인 프로젝트를 구성하기 위해 먼저 주기적인 회의 및 소통을 통해 팀 프로젝트의 진행방향을 잡아갔습니다. 먼저 캡스톤 디자인주제를 선정
sunho99.tistory.com
해당 글은 3장에 이어 추가적으로 작성을 하고 있습니다. 과정을 보고 싶으신 분은 1장부터 차례대로 보시면 될 것 같습니다.
3장까지 진행한 결과를 요약하자면 서울시 실시간 인구 데이터를 바탕으로 인구예측 모델을 통해 인구 혼잡 정보를 사용자에게 제공했습니다. 인구데이터에 대해 '왜 사람들이 특정 지역에 모이는가?' 라는 의문을 가질 수 있는데 해당 궁금증을 해소하기 위해 지역별 트렌드를 분석하여 제공하도록 했습니다.
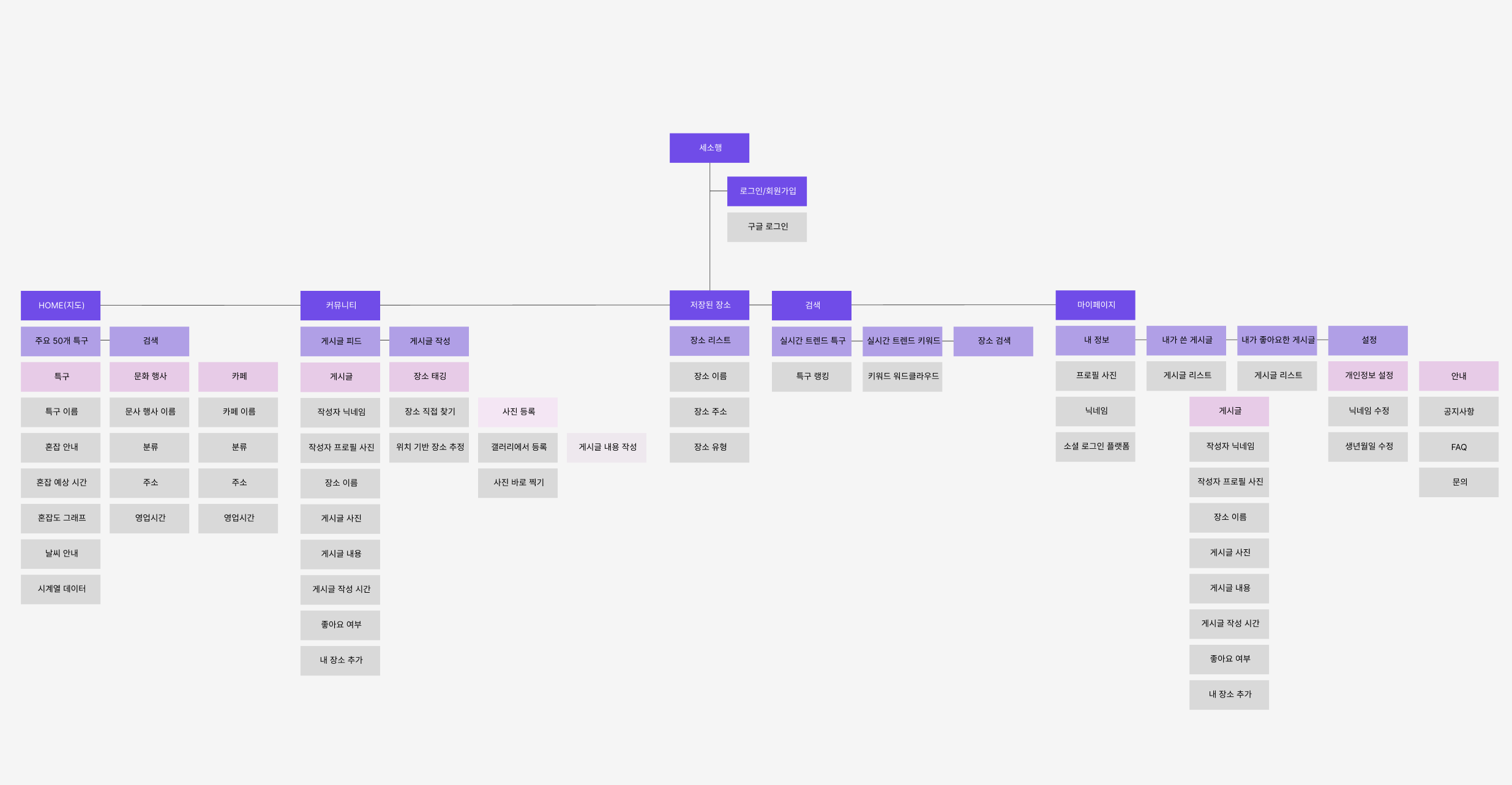
위는 모바일 어플리케이션 설계도 입니다. 저희 팀은 트렌드 분석을 위해 게시물 기능을 추가하여 저희가 갖고있는 카페와 문화 데이터에 게시물을 작성할 수 있도록 하였습니다.

사용자는 지역별 위치하고 있는 카페 정보와 문화 정보에 대해 마커 UI를 통해 정보를 접할 수 있습니다. 이를 통해 사용자는 해당 장소에 대해 정보를 확인할 수 있으며, 추가적으로 해당 장소에 대한 소비를 진행했다면, SNS 형식으로 게시물을 작성할 수 있도록 했습니다.

해당 예시 데이터처럼 카멜 커피라는 장소에 대해 게시물을 작성할 수 있는데 해당 카멜 커피가 어떤 특정 지역(ex) 성수 카페거리)에 포함되어 있는지 ERD 설계 및 데이터베이스 구축을 통해 지역별 게시물 데이터를 확보 할 수 있었습니다.
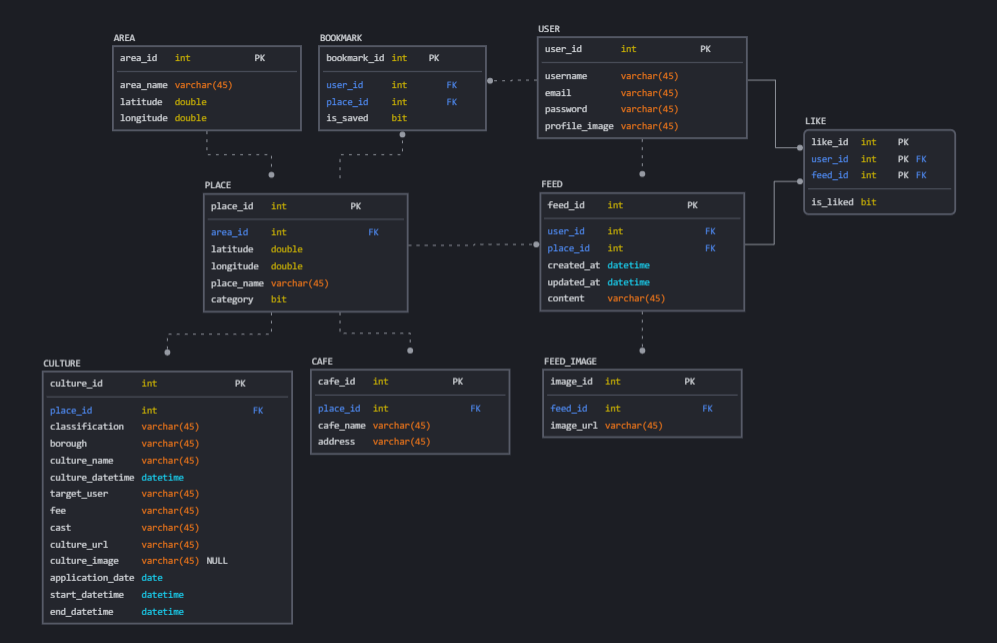
해당 데이터베이스를 이용하여 query문을 통해 지역에 대한 게시물데이터를 확보 할 수 있었습니다. 다음 이미지는 진행 과정입니다.
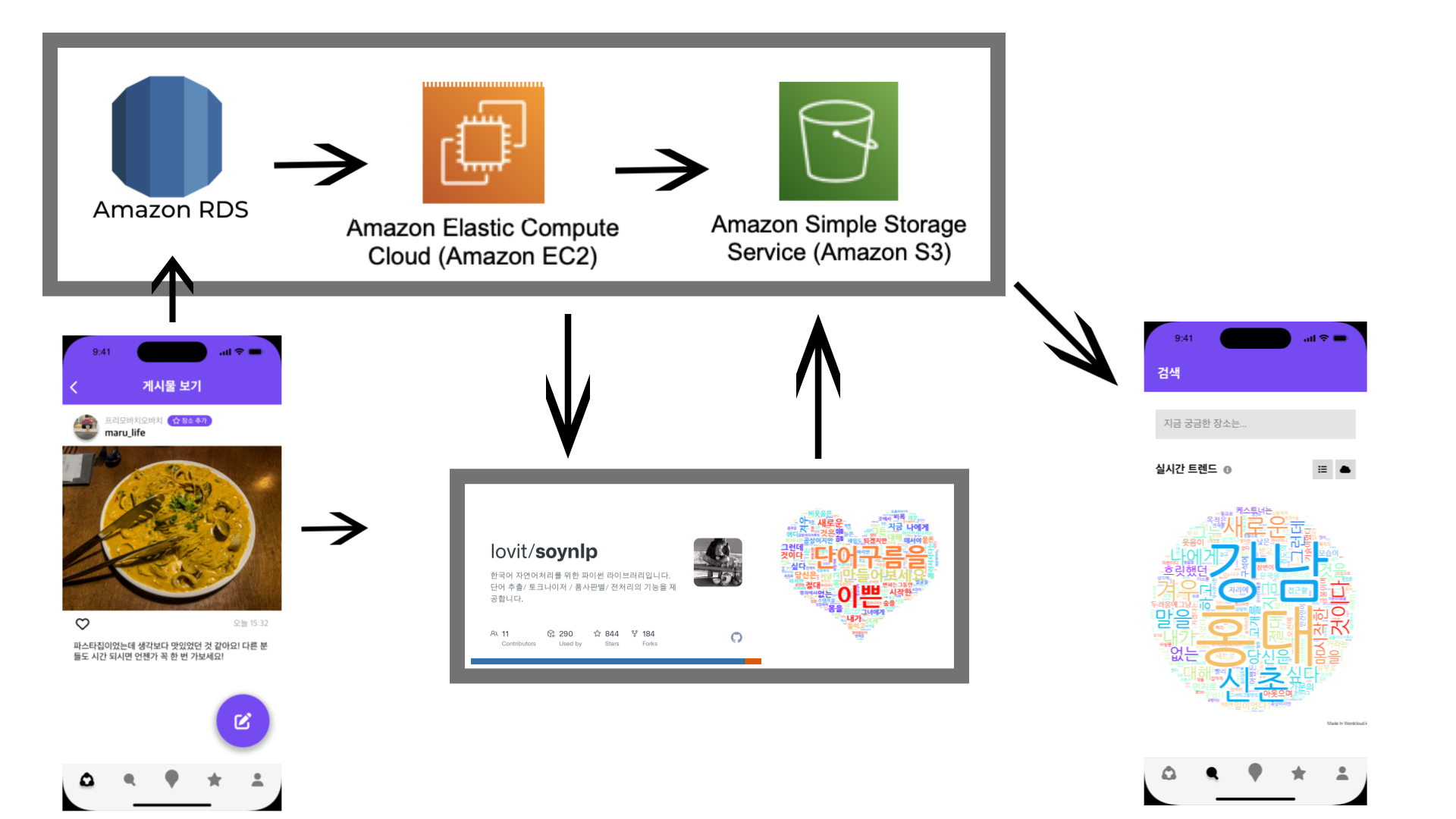
사용자가 게시물을 작성하면 해당 게시물은 RDS에 적재하게 되며, EC2에서 RDS와 연동을 하고 query를 통해 데이터를 추출합니다. 해당 데이터를 바탕으로 자연어 처리 오픈소스인 soynlp를 사용하여 wordcloud를 진행했습니다. 이때 사용자 게시물을 가져오는 것은 상당히 주관적인 정보를 포함하고 있으므로, 뉴스 데이터를 같이 접목하여 주관적인 데이터에 객관적인 정보를 더했습니다.
import time
import pymysql
import csv
import pandas as pd
from konlpy.tag import Okt
from soynlp.normalizer import *
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import matplotlib as mpl
from collections import Counter
import re
import numpy as np
from PIL import Image
import boto3
import io
import os
import schedule
from bs4 import BeautifulSoup as bs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import pandas as pd
import requests
def job():
try:
# S3 클라이언트 생성
s3 = boto3.client('s3', aws_access_key_id="AKI####U", aws_secret_access_key="/ZMZI7E###")
host = 'sesohaeng.cf3###t.ap-northeast-2.rds.amazonaws.com'
user = 'sesohaeng'
port = 3306
password = 'ssh-##0'
database = 'sesohaeng_db'
conn = pymysql.connect(host=host,port=port,user=user, password=password, database=database)
cursor = conn.cursor()
# feed,place,area
query = "SELECT area_name,content FROM place LEFT JOIN feed ON place.id = feed.place_id JOIN area ON place.area_id = area.id WHERE length(content)>=1"
cursor.execute(query) # 쿼리 실행
results = cursor.fetchall()
# CSV 파일로 저장
csv_filename = 'query_results.csv'
with open(csv_filename, 'w', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow([i[0] for i in cursor.description]) # 헤더 생성
csv_writer.writerows(results)
# 연결 종료
cursor.close()
conn.close()
df = pd.read_csv("/home/ubuntu/wordcloud/query_results.csv")
combined_reviews = df.groupby('area_name')['content'].apply(list).reset_index()
for index, row in combined_reviews.iterrows():
area_name = row['area_name']
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--headless")
# linux 환경에서 필요한 option
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
#options.add_argument("--disable-blink-features=AutomationControlled")
#options.add_experimental_option("excludeSwitches", ["enable-automation"])
#options.add_experimental_option("useAutomationExtension", False)
#options.add_experimental_option("prefs", {"prfile.managed_default_content_setting.images": 2})
driver = webdriver.Chrome(
executable_path='chromedriver',chrome_options=chrome_options)
area_name = row['area_name']
url = 'https://news.google.com/?hl=ko&gl=KR&ceid=KR%3Ako'
driver.get(url)
driver.implicitly_wait(3)
keywords = area_name
search = driver.find_element(By.XPATH,
'//*[@id="gb"]/div[2]/div[2]/div/form/div[1]/div/div/div/div/div[1]/input[2]')
search.send_keys(keywords)
search.send_keys(Keys.ENTER)
driver.implicitly_wait(30)
url = driver.current_url
resp = requests.get(url)
soup = bs(resp.text, 'lxml')
titles = [] # new 제목
for link in soup.select('h3 >a'):
href = 'https://news.google.com' + link.get('href')[1:]
title = link.string
titles.append(title)
driver.quit()
review_data = row['content']
if len(review_data) < 10:
continue
total_reviews = []
for review in review_data:
total_reviews.append(review)
okt = Okt()
total_reviews = total_reviews + titles
normalization_total_review = []
# 문장 이상한거 수정 및 정규화 진행 전처리
for review in total_reviews: # 긍정리뷰
pattern = '([ㄱ-ㅎㅏ-ㅣ]+)' # 한글 자음, 모음 제거
review = re.sub(pattern=pattern, repl='', string=review)
pattern = '<[^>]*>' # HTML 태그 제거
review = re.sub(pattern=pattern, repl='', string=review)
pattern = '[^\w\s\n]' # 특수기호제거
review = re.sub(pattern=pattern, repl='', string=review)
clean_review = emoticon_normalize(review, num_repeats=3) # 반복되는 이모티콘 정리 최대 3회
clean_review = repeat_normalize(clean_review, num_repeats=3) # 반복되는 문구 정리 최대 3회
clean_review = only_hangle(clean_review) # 리뷰중 영어 제외
clean_review = okt.normalize(clean_review) # 정리
normalization_total_review.append(clean_review)
pos_reviews = []
for review in normalization_total_review: # 형태소 분석
clean_review = okt.pos(review, stem=True, join=True)
pos_reviews.append(clean_review)
# {'Adjective': '형용사',
# 'Adverb': '부사',
# 'Alpha': '알파벳',
# 'Conjunction': '접속사',
# 'Determiner': '관형사',
# 'Eomi': '어미',
# 'Exclamation': '감탄사',
# 'Foreign': '외국어, 한자 및 기타기호',
# 'Hashtag': '트위터 해쉬태그',
# 'Josa': '조사',
# 'KoreanParticle': '(ex: ㅋㅋ)',
# 'Noun': '명사',
# 'Number': '숫자',
# 'PreEomi': '선어말어미',
# 'Punctuation': '구두점',
# 'ScreenName': '트위터 아이디',
# 'Suffix': '접미사',
# 'Unknown': '미등록어',
# 'Verb': '동사'}
tag_reviews = []
for i in pos_reviews: # 형용사 , 명사 가져오기
for j in i:
text_tag = j.split("/") # '편리하다/Adjective'
if text_tag[1] == "Noun":
tag_reviews.append(text_tag[0])
# 가장 많이 나온 단어부터 30개를 저장한다.
count_tag_reviews = Counter(tag_reviews)
tags = count_tag_reviews.most_common(50)
# WordCloud를 생성한다.
# 한글을 분석하기위해 font를 한글로 지정해주어야 된다. macOS는 .otf , window는 .ttf 파일의 위치를
# 지정해준다. (ex. '/Font/GodoM.otf')
masking_image = np.array(Image.open("/home/ubuntu/wordcloud/img2.png"))
wc = WordCloud(font_path="/usr/share/fonts/truetype/nanum/NanumGothic.ttf",
random_state=123, background_color="white", max_font_size=200, max_words=30,
width=2000, height=1000,
mask=masking_image, # masking
colormap='rainbow'
)
cloud = wc.generate_from_frequencies(dict(tags))
# 생성된 WordCloud를 test.jpg로 보낸다.
cloud.to_file("%s.jpg"%area_name)
plt.rcParams["font.family"] = 'NanumGothic' # 한글 폰트 적용
mpl.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10, 10))
plt.axis('off')
plt.imshow(cloud, interpolation='bilinear')
#plt.title("%s 트랜드"%area_name)
plt.savefig("%s.jpg" % area_name) # 각 구에 맞는 나이 비율 이미지
plt.close()
output_filename = "%s.jpg" % area_name
file_name = output_filename
file_path = os.path.realpath(output_filename)
# # # S3 버킷 이름과 업로드할 객체 키를 지정합니다.
bucket_name = 'mlops-models-bucket'
object_key = "wordcloud/" + "%s/" % area_name + file_name
# 로컬 파일을 S3에 업로드합니다.
s3.upload_file(file_path, bucket_name, object_key)
except ValueError:
pass
schedule.every(5).minutes.do(job)
while True:
schedule.run_pending()
time.sleep(1)
query문을 통해 데이터를 조회하며 해당 데이터를 가져오고 이를 wordcloud로 표현하는 코드입니다. 이때 추가적으로 뉴스데이터를 합쳐 진행합니다.
from bs4 import BeautifulSoup as bs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import pandas as pd
import requests
options = webdriver.ChromeOptions()
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
options.add_experimental_option("prefs", {"prfile.managed_default_content_setting.images": 2})
driver = webdriver.Chrome(executable_path='/Users/sunho99/PycharmProjects/python_Project/캡스톤디자인/wordcloud_test/chromedriver', options=options)
keyword_data = []
url = 'https://news.google.com/?hl=ko&gl=KR&ceid=KR%3Ako'
driver.get(url)
driver.implicitly_wait(3)
keywords = input('Search keyword: ')
search = driver.find_element(By.XPATH,'//*[@id="gb"]/div[2]/div[2]/div/form/div[1]/div/div/div/div/div[1]/input[2]')
search.send_keys(keywords)
search.send_keys(Keys.ENTER)
driver.implicitly_wait(30)
url = driver.current_url
resp = requests.get(url)
soup = bs(resp.text, 'lxml')
titles = []
for link in soup.select('h3 >a'):
href = 'https://news.google.com' + link.get('href')[1:]
title = link.string
titles.append(title)
print(titles)
해당 데이터를 통해 뉴스 헤드라이드 기사를 가져오며 데이터를 합쳐 wordcloud를 진행했습니다.
그 결과 지역별로 다른 키워드들이 추출됐으며 이를 통해 지역별 트렌드 및 특징을 사용자가 확인 할 수 있었습니다.


이를 통해 지역별 특징이 분리되어 나타났으며, 소비자는 해당 인구가 왜 모이는지에 대한 의문을 해소 할 수 있었습니다. 당시 프로젝트를 진행하면서 카드사 소비데이터를 바탕으로 지역별 특징을 나타내려 했는데, 앱 특성상 실시간으로 정보를 제공하는 취지에 있어 실시간 소비데이터를 구할 수 없다는 문제점에 직면하여 위 프로세스로 진행을 했습니다.
또한 현재 많이 작성되고 있는 게시물 순위를 UI를 통해 보여주며 MZ 세대의 '디깅 소비' 욕구를 증진시켰습니다.

이를 통해 사용자는 인구데이터와 지역별 트렌드를 확인할 수 있었습니다.
'캡스톤디자인프로젝트' 카테고리의 다른 글
| 캡스톤디자인 회고 및 프로젝트 정리 5장 - 마무리 - (2) | 2023.11.09 |
|---|---|
| 캡스톤디자인 회고 및 프로젝트 정리 3장 (3) | 2023.11.09 |
| 캡스톤디자인 회고 및 프로젝트 정리 2장 (0) | 2023.08.02 |
| 캡스톤디자인 회고 및 프로젝트 정리 1장 (2) | 2023.07.31 |