
캡스톤디자인 회고 및 프로젝트 정리 2장
캡스톤디자인 프로젝트를 구성하기 위해 먼저 주기적인 회의 및 소통을 통해 팀 프로젝트의 진행방향을 잡아갔습니다. 먼저 캡스톤 디자인주제를 선정하기에 있어 상당히 많은 노력과 리서치
sunho99.tistory.com
해당 글은 2장에 이어 추가적으로 작성을 하고 있습니다. 과정을 보고 싶으신 분은 1장부터 차례대로 보시면 될 것 같습니다.
2장에서 API 통신을 통해 1시간마다 데이터를 적재하며 시계열 데이터를 구축했습니다. 해당 데이터를 바탕으로 Prophet 모델을 사용하여 인구 모델 데이터 예측을 진행했습니다.
import pandas as pd
import numpy as np
from prophet import Prophet
from datetime import datetime, timedelta
import holidays
import os
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
import boto3
from matplotlib import rc, font_manager
# from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error
import matplotlib as mpl
import io
import schedule
import time
# def job():
# S3 버킷 및 파일 경로
bucket_name = 'mlops-api-output'
file_key = '2023/2023.csv'
# S3 클라이언트 생성
s3 = boto3.client('s3', aws_access_key_id="AKI###", aws_secret_access_key="/ZMZI7###")
# CSV 파일 다운로드 및 읽기
response = s3.get_object(Bucket=bucket_name, Key=file_key)
df = pd.read_csv(io.BytesIO(response["Body"].read()))
df_index_list = df.index
df.insert(0,"지역",df_index_list)
df_reset= df.reset_index(drop=True)
df_reset['PPLTN_TIME']=df_reset['PPLTN_TIME'].apply(lambda _ : datetime.strptime(_,'%Y-%m-%d %H:%M'))
df_reset['PPLTN_TIME'] = df_reset['PPLTN_TIME'].dt.strftime('%Y-%m-%d %H:00:00')
local_list = df_reset["지역"].unique()
# 한국 휴일 객체 생성
kr_holidays = holidays.KR()
df_reset['holiday'] = df_reset.PPLTN_TIME.apply(lambda x: True if x in kr_holidays else False)
df = df_reset.rename(columns={'PPLTN_TIME': 'ds', 'AREA_PPLTN_MAX': 'y'})
df['ds'] = pd.to_datetime(df['ds'])
for i in local_list:
plt.clf() # plt 초기화
local_df = df["지역"] == "광화문·덕수궁" # "지역" column에서 "경복궁" 값을 가지고 있는 행 추출
print(i)
filtered_local_df = df[local_df]
# 날짜를 기준으로 정렬
filtered_local_df = filtered_local_df.sort_values('ds', ascending=False)
# 오늘 날짜 가져오기
# latest_date = filtered_local_df.iloc[0]['ds']
today = datetime.today().strftime("%Y-%m-%d 00:00:00")
latest_date = datetime.today().strptime(today, "%Y-%m-%d 00:00:00")
# 최근 n 일 동안의 데이터 선택
start_date = latest_date - timedelta(days=30)
new_df = filtered_local_df[filtered_local_df['ds'] >= start_date]
test_day = latest_date
new_df = new_df[new_df['ds'] <= test_day]
# print(df['ds'])
new_df = new_df.sort_values('ds', ascending=True)
model = Prophet(
#Trend
growth="linear",
changepoints=None,
n_changepoints=10,
changepoint_range=1,
changepoint_prior_scale=0.5,
interval_width=0.95,
#Holiday
holidays=None)
model.fit(new_df)
# 미래 예측 생성
future = model.make_future_dataframe(freq="H",periods=24)
# print(future)
# 미래 예측
forecast = model.predict(future)
test_day = latest_date
start_day = test_day - timedelta(days=1)
test = new_df[new_df['ds'] > start_day]
train = forecast[forecast['ds'] <= test_day]
train = train[train['ds'] > start_day]
# print(train)
# print(train.info())
predict = forecast[forecast['ds'] >= test_day]
forecast = forecast[forecast['ds'] > start_day]
# 관측된 데이터 포인트 제거
# print(model.history.y)
# future_predictions = forecast[df.shape[0]:]
model.history.loc[:new_df.shape[0], 'y'] = None
# 시각화
fig = model.plot(forecast)
ax = fig.gca()
# x 축 눈금 설정
locator = mdates.HourLocator(interval=2) # 2시간 간격으로 눈금 설정
formatter = mdates.DateFormatter('%m-%d %H') # 날짜 형식 지정
ax.xaxis.set_major_locator(locator)
ax.xaxis.set_major_formatter(formatter)
plt.rcParams["font.family"] = 'NanumGothic' # 한글 폰트 적용
mpl.rcParams['axes.unicode_minus'] = False
# x축 눈금 설정
plt.gca().spines['right'].set_visible(False) # 오른쪽 테두리 제거
#plt.gca().spines['top'].set_visible(False) # 위 테두리 제거
plt.gca().spines['left'].set_visible(False) # 왼쪽 테두리 제거
plt.gca().set_facecolor('#E6F0F8') # 배경색
# fcst_t = forecast['ds'].dt.to_pydatetime()
# ax.plot(model.history['ds'].dt.to_pydatetime(), model.history['y'], color = 'black')
ax.spines['left'].set_visible(False) # 왼쪽 여백 제거
ax.spines['top'].set_visible(False) # 위쪽 여백 제거
line0 = ax.fill_between(forecast['ds'], forecast['yhat_lower'], forecast['yhat_upper'], color='#edade4', alpha=0.3,label='bound') # 범주값 표시
line1, = ax.plot(test['ds'], test['y'],color = 'black',label = 'Real data')
line2, = ax.plot(predict['ds'], predict['yhat'], color='#8d2edb',label='Predict data') # 예측 값
line3,= ax.plot(train['ds'], train['yhat'], color='#e64f3e', label='model data') # 실제값 추이
# yticks = list(ax.get_yticks()) ## y축 눈금을 가져온다.
#
# for y in yticks:
# ax.axhline(y, linestyle=(0, (5, 2)), color='grey', alpha=0.5) ## 눈금선 생성
#plt.title("%s 인구혼잡도" % i, weight='bold',fontsize=10)
plt.xlabel("날짜")
plt.xticks(rotation=45, ha='right',weight='bold')
plt.ylabel('인구혼잡도', rotation='vertical', ha='right',weight='bold')
ax.legend(handles=[line0, line1, line2, line3], loc='upper left', fontsize=8,
labels=['예측값범위', '실제 값', '예측 값','모델 결과값'], edgecolor='black', shadow=True)
plt.savefig("%s_model.png" % i,bbox_inches = 'tight') # 각 구에 맞는 나이 비율 이미지
# plt.show()
plt.close()
output_filename = "%s_model.png" % i
file_name = output_filename
file_path = os.path.realpath(output_filename)
# # # S3 버킷 이름과 업로드할 객체 키를 지정합니다.
bucket_name = 'mlops-models-bucket'
object_key = "prophet/" + "%s/" % i + file_name
# 로컬 파일을 S3에 업로드합니다.
s3.upload_file(file_path, bucket_name, object_key)
# break
# schedule.every().day.at("00:05").do(job)
while True:
schedule.run_pending()
time.sleep(1)
해당 코드를 통해 30일간의 인구 데이터를 기반으로 당일날 예측 데이터 시각화를 진행했습니다.

위 이미지가 서울 50 개 지역중 쌍문동 맛집거리에 대한 모델 예측 결과 예시입니다.
사용자는 해당 데이터를 바탕으로 전날까지의 실제 유동인구의 데이터를 볼 수 있으며, 추가적으로 당일날 인구 예측값을 확인 할 수 있었습니다.



또한 지역별로 나이대 분포도와 남녀 성비, 주간혼잡도를 보여주며, 해당 지역에서 나이대 분포를 통해 지역별 특징을 나타냈습니다. 위 데이터를 바탕으로 MZ세대에서 인기있는 홍대, 건대 등 특정 지역에 있어 20대와 30대 분포가 많은 것을 확인 할 수 있었습니다. 또한 모델의 정확도를 측정하기 위해 RMSE 지표를 추출했습니다. 모델의 예측 결과값과 실제 데이터 값의 RMSE 도출을 통해 모델 정확도를 판별할 수 있었습니다.
import pandas as pd
import numpy as np
from prophet import Prophet
from datetime import datetime, timedelta
import holidays
import os
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
import boto3
import matplotlib as mpl
import io
from sklearn.metrics import mean_squared_error
import math
# S3 버킷 및 파일 경로
bucket_name = 'mlops-api-output'
file_key = '2023/2023.csv'
# S3 클라이언트 생성
s3 = boto3.client('s3', aws_access_key_id="AKIA3IWALKWTEQNRFASU",
aws_secret_access_key="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")
# CSV 파일 다운로드 및 읽기
response = s3.get_object(Bucket=bucket_name, Key=file_key)
df = pd.read_csv(io.BytesIO(response["Body"].read()))
df_index_list = df.index
df.insert(0, "지역", df_index_list)
df_reset = df.reset_index(drop=True)
df_reset['PPLTN_TIME'] = df_reset['PPLTN_TIME'].apply(lambda _: datetime.strptime(_, '%Y-%m-%d %H:%M'))
df_reset['PPLTN_TIME'] = df_reset['PPLTN_TIME'].dt.strftime('%Y-%m-%d %H:00:00')
local_list = df_reset["지역"].unique()
# 한국 휴일 객체 생성
kr_holidays = holidays.KR()
df_reset['holiday'] = df_reset.PPLTN_TIME.apply(lambda x: True if x in kr_holidays else False)
df = df_reset.rename(columns={'PPLTN_TIME': 'ds', 'AREA_PPLTN_MAX': 'y'})
df['ds'] = pd.to_datetime(df['ds'])
# RMSE, y 평균값, yhat 평균값을 저장할 데이터프레임 생성
rmse_df = pd.DataFrame(columns=['지역', 'RMSE', 'y 평균값', 'yhat 평균값'])
for i in local_list:
plt.clf() # plt 초기화
local_df = df["지역"] == i # "지역" column에서 "경복궁" 값을 가지고 있는 행 추출
print(i)
filtered_local_df = df[local_df]
# 날짜를 기준으로 정렬
filtered_local_df = filtered_local_df.sort_values('ds', ascending=False)
# 오늘 날짜 가져오기
# latest_date = filtered_local_df.iloc[0]['ds']
today = datetime.today().strftime("%Y-%m-%d 00:00:00")
latest_date = datetime.today().strptime(today, "%Y-%m-%d 00:00:00")
# 최근 n 일 동안의 데이터 선택
start_date = latest_date - timedelta(days=30)
new_df = filtered_local_df[filtered_local_df['ds'] >= start_date]
test_day = latest_date
new_df = new_df[new_df['ds'] <= test_day]
# print(df['ds'])
new_df = new_df.sort_values('ds', ascending=True)
model = Prophet(
# Trend
growth="linear",
changepoints=None,
n_changepoints=10,
changepoint_range=1,
changepoint_prior_scale=0.5,
interval_width=0.95,
# Holiday
holidays=None)
model.fit(new_df)
# 미래 예측 생성
future = model.make_future_dataframe(freq="H", periods=24)
# print(future)
# 미래 예측
forecast = model.predict(future)
test_day = latest_date
start_day = test_day - timedelta(days=1) # 어제 날짜
test = new_df[new_df['ds'] > start_day]
predict = forecast[forecast['ds'] > test_day]
# 실제 값
actual_values = test['y']
# 예측 값
predicted_values = predict['yhat']
# RMSE 계산
rmse = round(math.sqrt(mean_squared_error(actual_values, predicted_values)),2)
# 평균 값 계산
mean_value = round(predicted_values.mean(),2)
# y의 평균값 계산
y_mean = round(actual_values.mean(),2)
# yhat의 평균값 계산
yhat_mean = round(predicted_values.mean(),2)
# 데이터프레임에 결과 값 추가
rmse_df = rmse_df.append({'지역': i, 'RMSE': rmse, 'y 평균값': y_mean, 'yhat 평균값': yhat_mean}, ignore_index=True)
# CSV 파일로 저장
rmse_df.to_csv('result.csv', index=False)
시각화 이미지는 s3 bucket에 저장됐으며 s3 bucket에 있는 이미지를 가져와 어플리케이션 내에서 해당 데이터를 보여줬습니다.
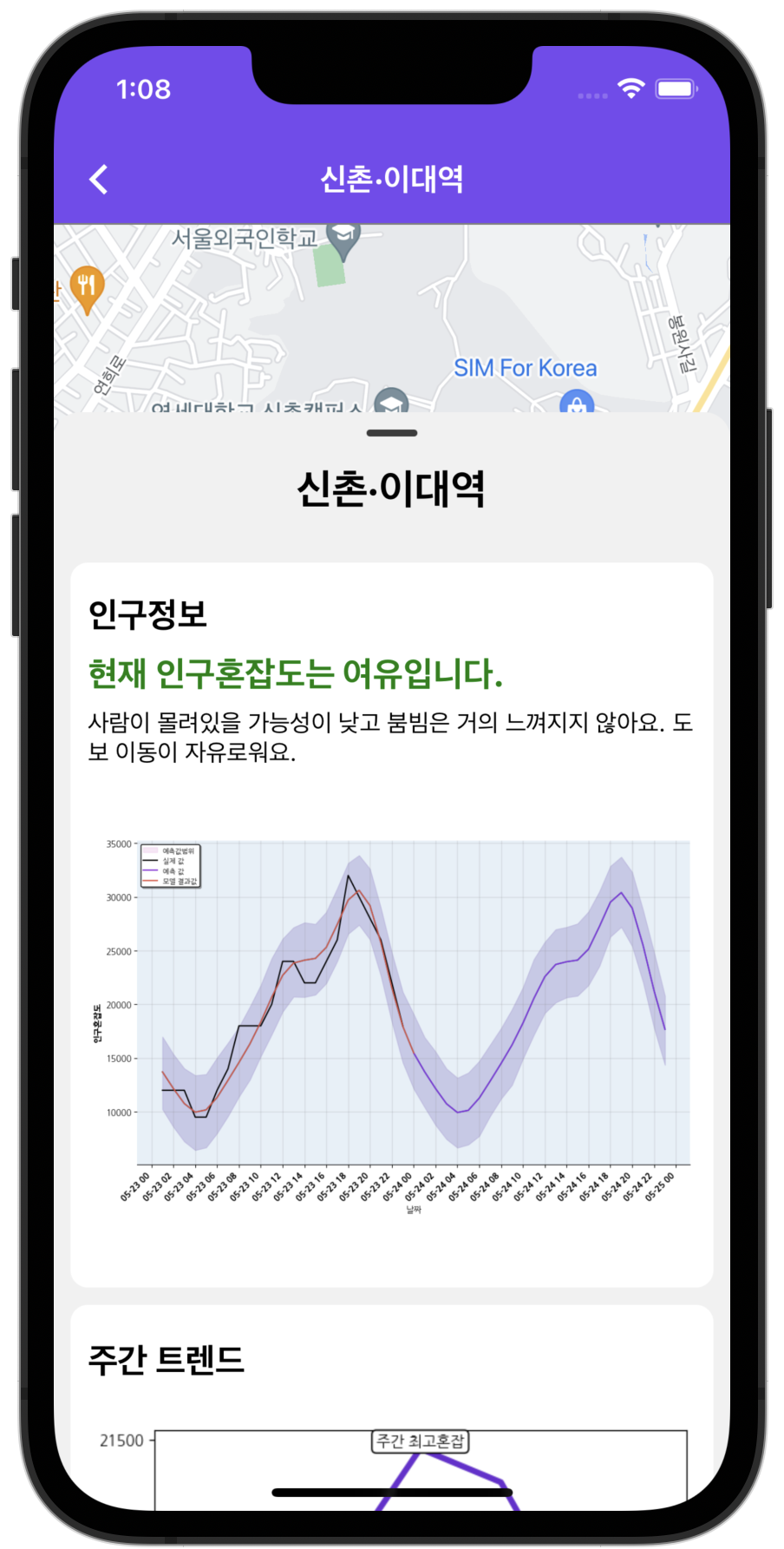
데이터를 실시간으로 1시간마다 계속해서 가져오기때문에 현재 인구혼잡도에 대한 정보를 지속적으로 갱신하며 제공했고 이를 통해 사용자들은 현재 자기가 원하고자 하는 지역에 대한 인구정보 통계및 인구혼잡도를 확인 할 수 있었습니다.
'캡스톤디자인프로젝트' 카테고리의 다른 글
| 캡스톤디자인 회고 및 프로젝트 정리 5장 - 마무리 - (2) | 2023.11.09 |
|---|---|
| 캡스톤디자인 회고 및 프로젝트 정리 4장 (2) | 2023.11.09 |
| 캡스톤디자인 회고 및 프로젝트 정리 2장 (0) | 2023.08.02 |
| 캡스톤디자인 회고 및 프로젝트 정리 1장 (2) | 2023.07.31 |