
LSTM 모델에 이어서 동일 데이터로 Transformer 모델에서 모델링을 진행하였습니다.
기존 LSTM 모델 결과를 확인하고 싶으시면 다음 링크로 들어가시면 됩니다. 감사합니다 :-)
LSTM으로 spam 데이터 판별
주제 설명 Spam data를 바탕으로 이를 spam인지 spam이 아닌지 판별을 하는 모델을 개발하였습니다. 해당 모델은 LSTM을 선정하여 진행하였습니다. LSTM(Long SHor-Term Memory)는 순환 신경망(recureent natural net
sunho99.tistory.com
주제 설명
보고서는 Transformer 모델을 사용하여 스팸 메세지를 감지하고 분류하는 과정에 대해 자세히 설명합니다. Transformer는 자연어 처리에 널리 사용되는 딥러닝 아키텍처로, 시퀀스 데이터를 처리하는 뛰어난 능력을 갖추고 있습니다. 이를 활용하여 스팸 메세지 분류 문제를 해결할 수 있습니다.
데이터 설명
이 프로젝트에서 사용된 데이터는 스팸과 스팸이 아닌 일반 메일로 레이블링된 이메일 데이터입니다. 데이터셋은 이메일의 본문 텍스트와 해당 이메일이 스팸인지 스팸이 아닌지를 나타내는 레이블로 구성되어있습니다. 해당 데이터는 LSTM 모델에서 사용한 데이터의 원본이며, 이를 바탕으로 split data를 통해 데이터를 분할하여 학습을 진행하였습니다.
문제 설명
스펨 메세지 분류 문제는 주어진 텍스트 메세지가 스팸인지 아닌지를 판별하는 이진 분류 문제입니다. 주어진 Transformer 모델은 텍스트 메세지를 입력으로 받아 확률 값을 출력하며, 0.5를 기준으로 임계값을 설정하여 스팸 여부를 결정합니다.
작동원리
Transformer모델은 시퀀스 데이터를 처리하는데 특화된 딥러닝 아키텍처입니다. 기존의 순차적인 처리 방식과 달리, Transformer는 입력 시퀀스 전체를 동시에 처리하여 효율적인 학습과 예측을 가능하게 합니다. 이를 위해 주요한 구성 요소인 Attention 메커니즘을 사용합니다.
Attention은 입력 시퀀스의 각 위치에서 다른 위치와의 상호작용을 측정하여 가중치를 계산하는 메커니즘입니다. 이를 통해 모델은 주요한 정보에 집중하고, 문맥을 파악하여 입력 시퀀스르 효과적으로 이해할 수 있습니다. Transformer 모델은 Multi-head Attention 메커니즘을 사용하여 여러 개의 Attention 계산을 병렬로 수행하고, 결과를 결합하여 최종적인 표현을 생성합니다.
작동은 총 6단계를 거쳐 진행합니다. 전처리, 텍스트 벡터화, 토큰 및 위치 임베딩, Transformer 레이어, 분류기, 모델 학습 및 평가를 진행합니다.
전처리
데이터를 처리하기 전에 전처리 과정을 수행합니다. 전처리 단계에서는 구두점을 공백으로 대체하며, 텍스트를 소문자로 변환하며, 앞뒤 공백을 제거하는 작업을 수행합니다.
텍스트 벡터화
텍스트 모델에 입력하기 위해 텍스트 벡터화 과정을 수행합니다. 이를 위해 TensorFlow의 TextVectorization 레이어를 사용합니다. 이 레이어는 텍스트를 정수 인덱스로 변환하고, 시퀀스의 최대 길이로 패딩하여 일관된 길이로 맟춥니다.
토큰 및 위치 임베딩
Transformer 모델에는 토큰 임베딩과 위치 임베딩이 필요합니다. 토큰 임베딩은 텍스트 토큰을 고정 차원의 벡터로 변환하는 역활을 합니다. 위치 임베딩은 입력 시퀀스의 각 위치에 대한 정보를 추가합니다. 이러한 임베딩을 생성하기 위해 TokenAndPositionalEmbedding 레이러를 정의하고 사용합니다.
Transformer 레이어
Transformer 레이어는 입력 시퀀스를 처리하여 특성을 추출하는 역할을 합니다. Multi-Head Attention과 Feedforward Network로 구성되어 있으며, Layer Normalization을 사용하여 학습을 진행합니다. 이를 위해 Transformer Layer를 정의하고 사용합니다.
분류기
분류 작업을 위해 Global Average Pooling과 Dropout을 적용한 후 , 최종 출력을 위해 Dense를 사용합니다. 활성화 함수로는 Sigmoid 함수를 사용하여 확률값을 계산합니다.
모델 학습 및 평가
모델을 컴파일 한후, 테스트 데이터를 사용하여 모델의 성능을 평가하고, 손실, 정확도, 정밀도, 재현율,AUC 값을 출력합니다.
결과분석
Transformer 모델을 사용하여 스팸 메세지를 분류하는 방법에 대해 보고서를 작성하였습니다. 전처리, 텍스트 벡터화, 토큰 및 위치 임베딩, Transformer Layer, 분류기 등의 단계를 거쳐 모델을 학습시키고 평가하는 과정을 상세하게 다루었습니다. 이를 통해 스팸 메세지 분류 문제를 해결하기 위한 전체적인 절차를 이해할 수 있었습니다.
코드 설명
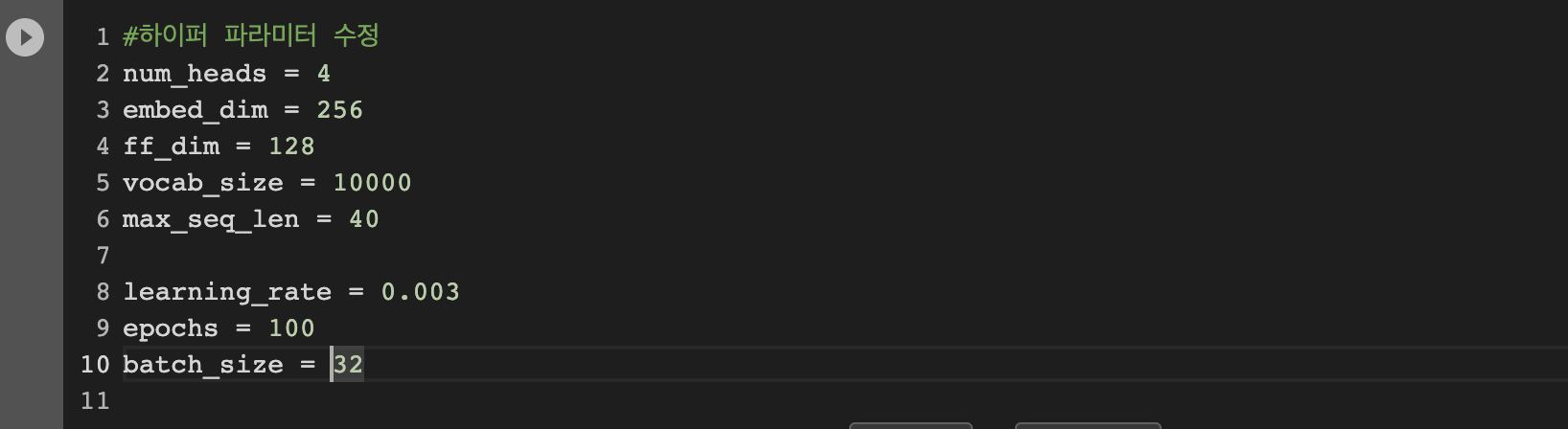
- ‘num_heads’는 Multi-Head Attention 에서 사용될 Head의 개수를 설정합니다.
- ‘embed_dim’ 은 임베딩 벡터의 차원을 나타냅니다.
- ‘ff_dim’은 Feedforward Network의 은닉층의 차원을 나타냅니다.
- ‘vocab_size’는 사용할 어휘 사전의 크기를 나타냅니다.
- ‘max_seq_len’ 은 입력 시퀀스의 최대 길이를 나타냅니다.
- ‘Learning_rage’는 모델의 학습률를 조정하는 파라미터입니다.
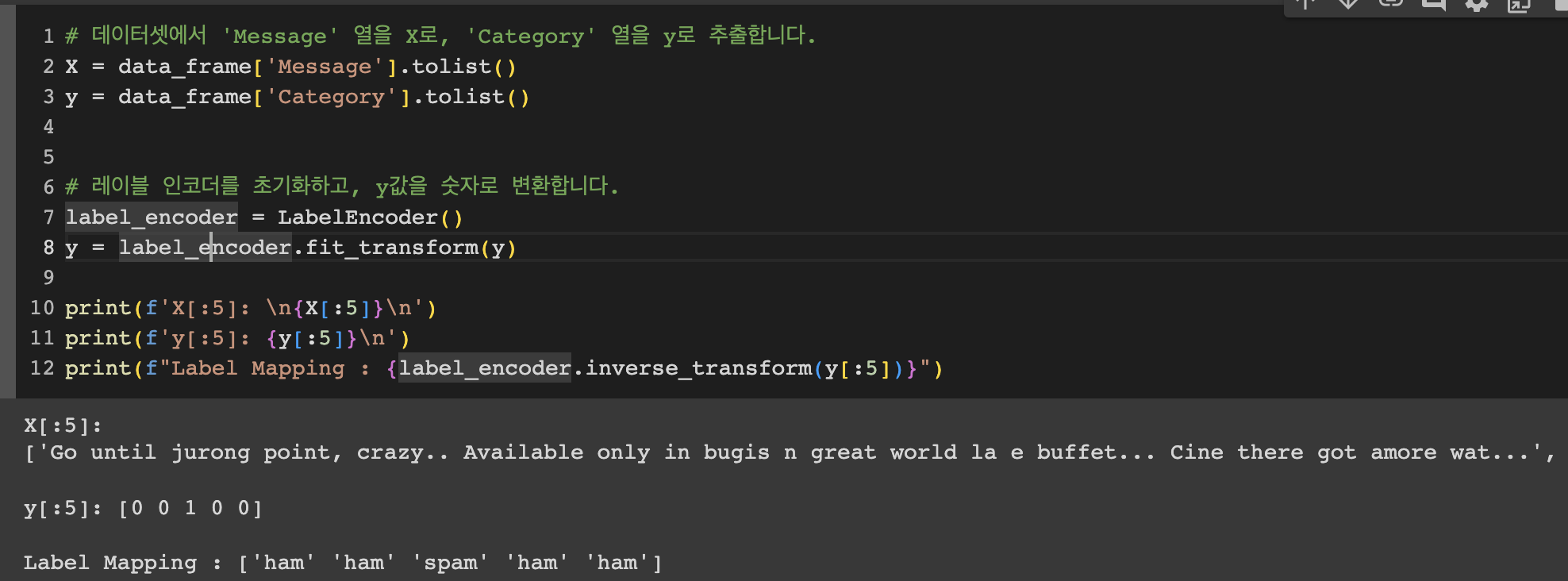
- 해당 코드를 통해 df에서 ‘Message’열을 추출하여 리스트 형태로 저장하며, ‘Category’열을 추출하여 리스트 형태로 저장하며 이를 타깃변수로 사용합니다. 레이블 인코더를 사용하여 카테고리에서의 ‘spam’을 1로, ‘ham’을 0으로 인코딩합니다.

데이터의 불균형을 보정하는 작업입니다.
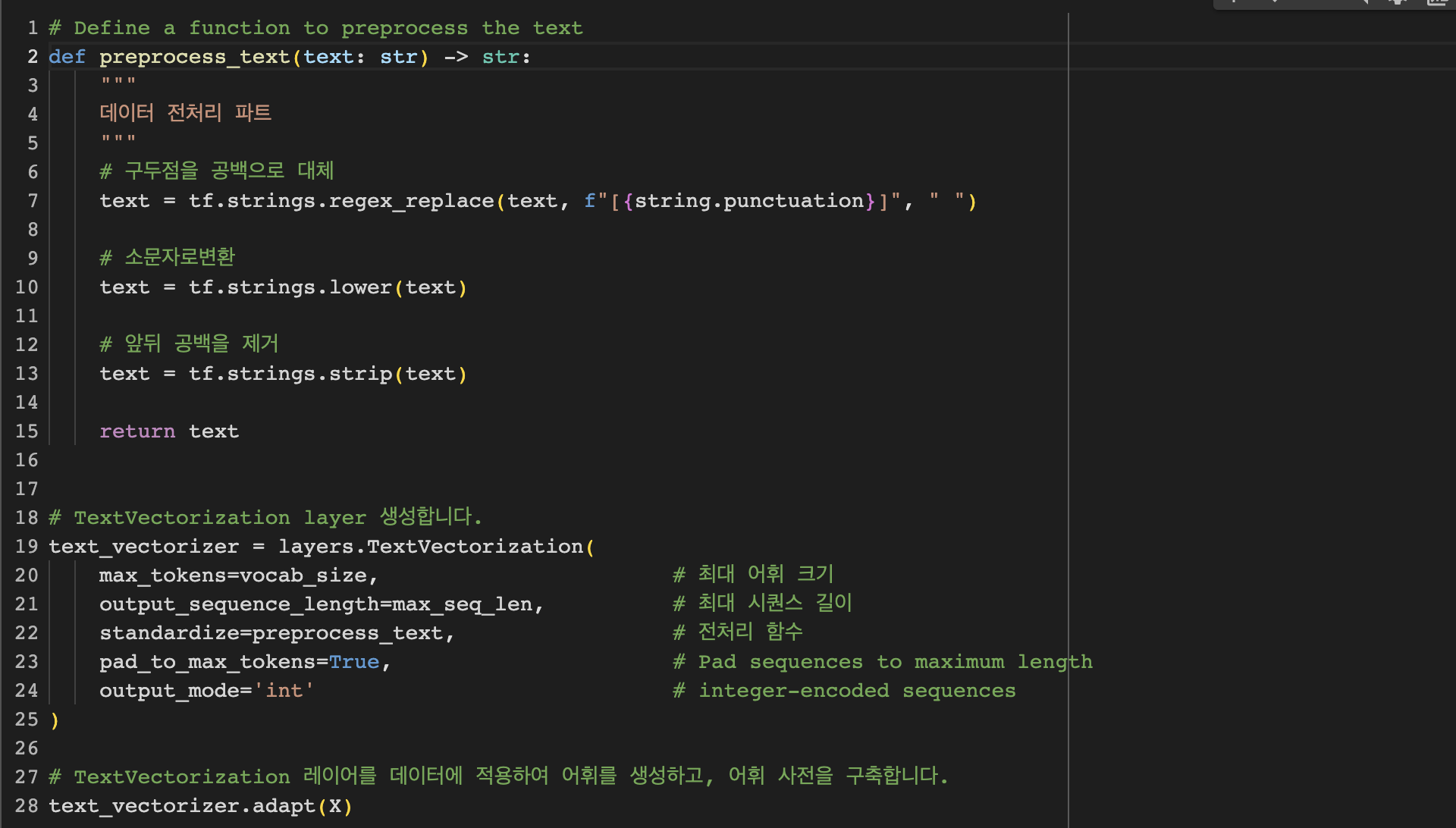
proprocess_text 함수를 통해 데이터를 전처리합니다. 이후 layers.TextVectorization 레이어를 생성하여, 텍스트 데이터를 어휘로 변환하는 역할을 수행하게 됩니다
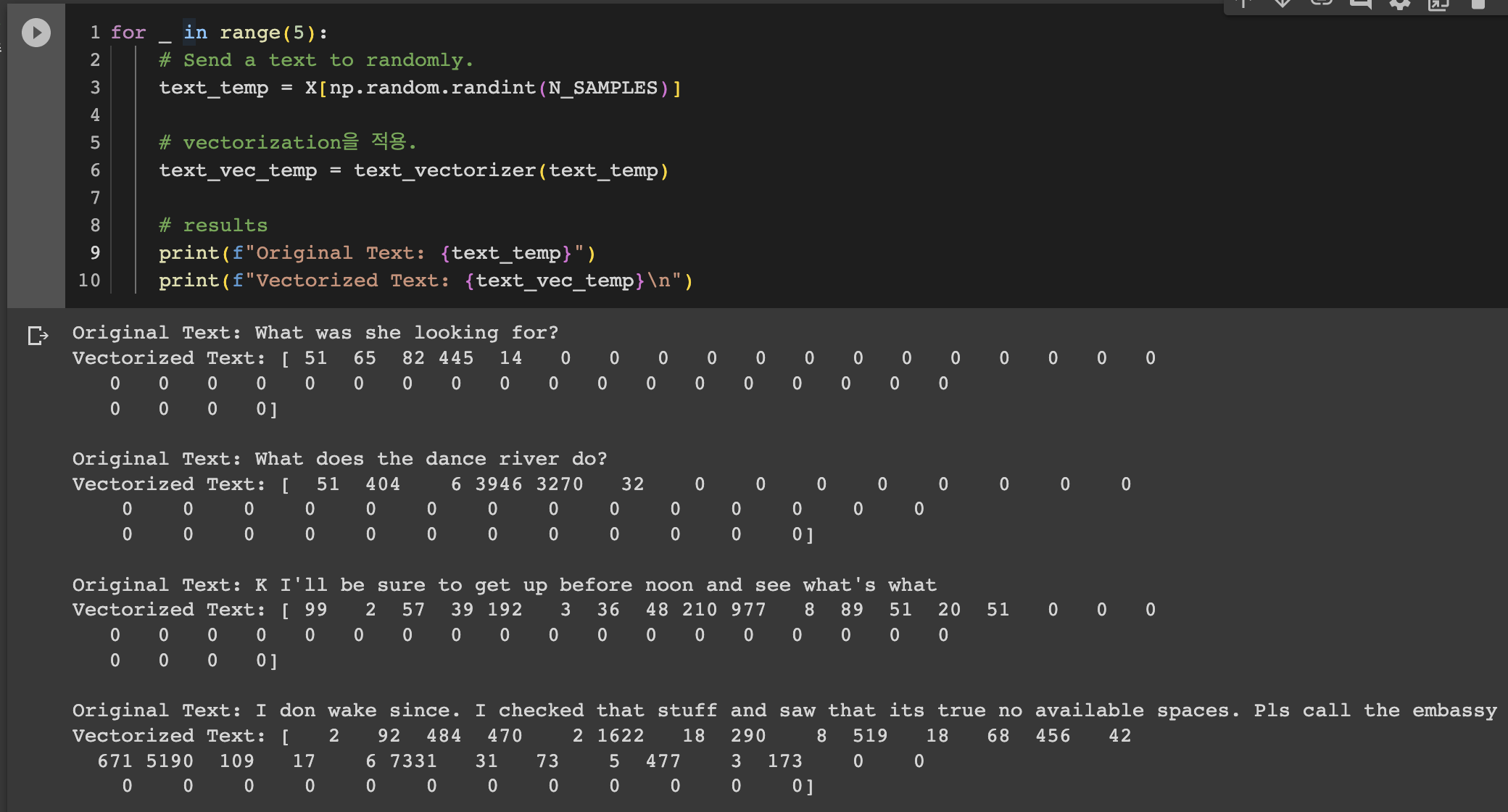
무작위로 선택한 text를 TextVectorization 레이어를 통해 벡터로 변환하고, 변환된 결과를 출력합니다. 이를 통해 어떻게 text가 벡터로 변환되는지 확인 할 수 있습니다.
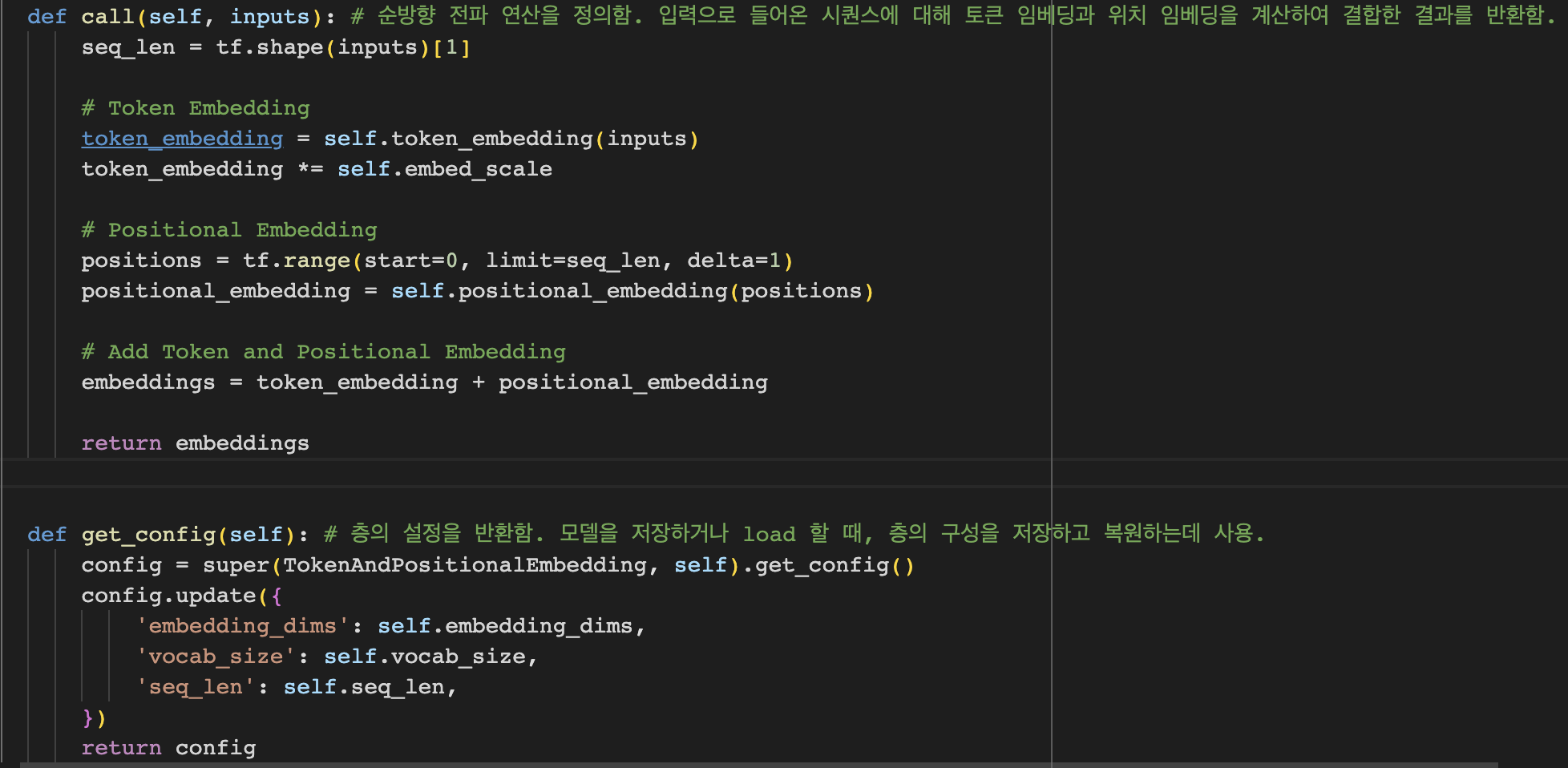
TokenAndPositionalEmbedding은 layers.Layer 클래스를 상속하여 사용자가 layer를 정의하는 부분입니다. __init__ 메서드는 클래스의 생성자로, 층의 초기화를 담당합니다. call의 메서드는 층의 순방향 전파 연산을 정의합니다.이를 통해 임베딩 벡터를 생성하여, 생성된 벡터는 Transformer 모델의 입력으로 사용됩니다.
Transformer 레이어를 정의하는 부분입니다. MultiheadAttention 레이어를 생성하는 부분이며, inputs을 세번 사용하여 query, key, value를 받습니다.
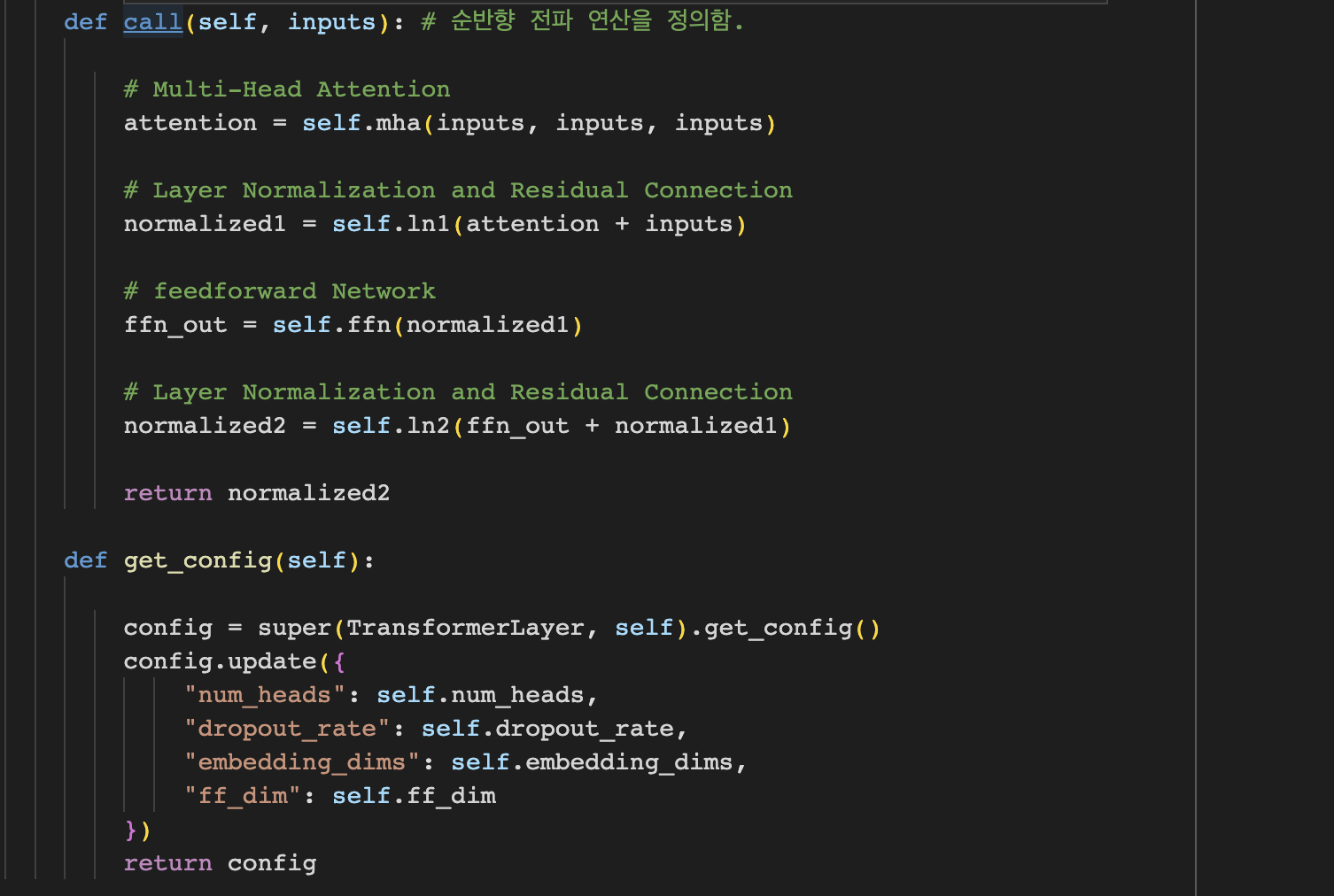
call메서드는 층의 순방향 전파 연상을 통해, 입력으로 들어온 sequence에 대해 multi-head attention과 feed-forward 네트워크를 적용한 후, 정규화및 Residual Connection을 수행하여 출력을 반환합니다.Transformer 레이어를 정의하는 부분입니다. MultiheadAttention 레이어를 생성하는 부분이며, inputs을 세번 사용하여 query, key, value를 받습니다. call메서드는 층의 순방향 전파 연상을 통해, 입력으로 들어온 sequence에 대해 multi-head attention과 feed-forward 네트워크를 적용한 후, 정규화및 Residual Connection을 수행하여 출력을 반환합니다.
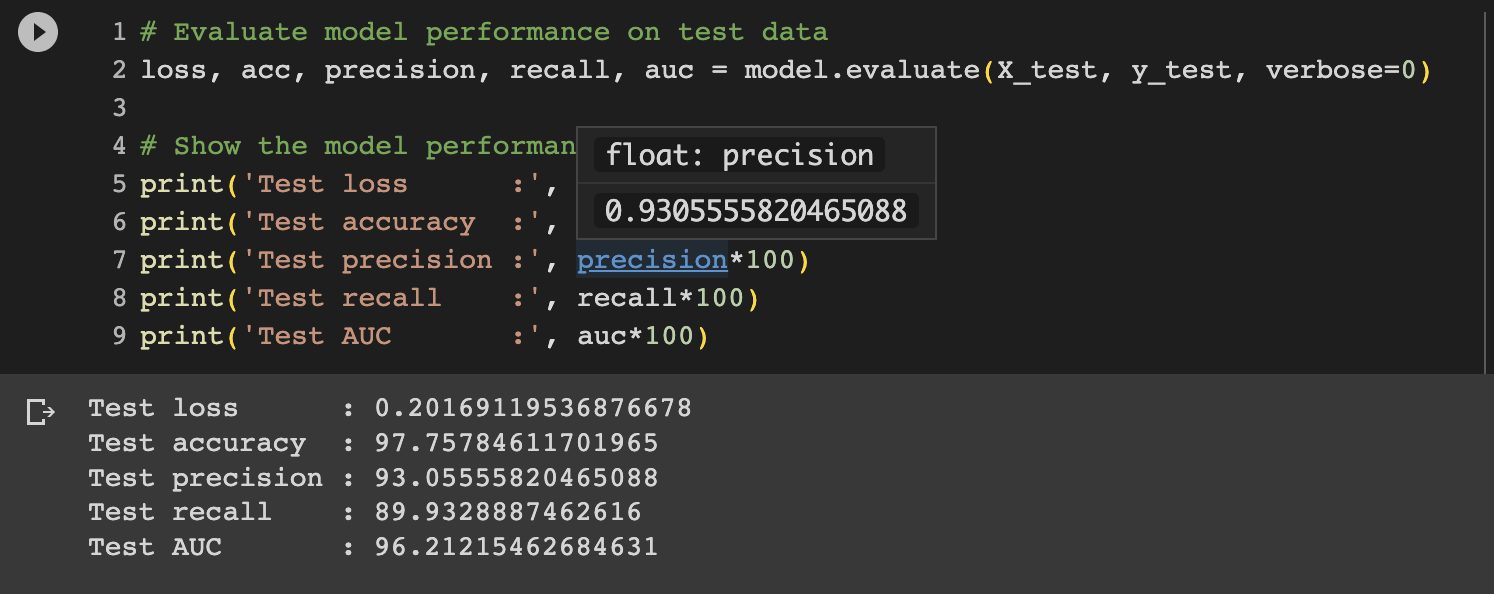
이후 model fit을 통해 학습을 진행합니다. 아래는 해당 model의 train결과 값입니다.
'AI > AI Project' 카테고리의 다른 글
| covid 데이터 선형회귀 (0) | 2023.09.13 |
|---|---|
| Spark MLLib Titanic Data - MulticlassClassification (0) | 2023.09.12 |
| Yolov5모델로 쓰레기 탐지하기 (0) | 2023.09.12 |
| LSTM으로 spam 데이터 판별 (0) | 2023.09.07 |
| 한국어 리뷰 감정 사전 구축하기 using soynlp and konlyp (0) | 2023.02.11 |
LSTM 모델에 이어서 동일 데이터로 Transformer 모델에서 모델링을 진행하였습니다.
기존 LSTM 모델 결과를 확인하고 싶으시면 다음 링크로 들어가시면 됩니다. 감사합니다 :-)
LSTM으로 spam 데이터 판별
주제 설명 Spam data를 바탕으로 이를 spam인지 spam이 아닌지 판별을 하는 모델을 개발하였습니다. 해당 모델은 LSTM을 선정하여 진행하였습니다. LSTM(Long SHor-Term Memory)는 순환 신경망(recureent natural net
sunho99.tistory.com
주제 설명
보고서는 Transformer 모델을 사용하여 스팸 메세지를 감지하고 분류하는 과정에 대해 자세히 설명합니다. Transformer는 자연어 처리에 널리 사용되는 딥러닝 아키텍처로, 시퀀스 데이터를 처리하는 뛰어난 능력을 갖추고 있습니다. 이를 활용하여 스팸 메세지 분류 문제를 해결할 수 있습니다.
데이터 설명
이 프로젝트에서 사용된 데이터는 스팸과 스팸이 아닌 일반 메일로 레이블링된 이메일 데이터입니다. 데이터셋은 이메일의 본문 텍스트와 해당 이메일이 스팸인지 스팸이 아닌지를 나타내는 레이블로 구성되어있습니다. 해당 데이터는 LSTM 모델에서 사용한 데이터의 원본이며, 이를 바탕으로 split data를 통해 데이터를 분할하여 학습을 진행하였습니다.
문제 설명
스펨 메세지 분류 문제는 주어진 텍스트 메세지가 스팸인지 아닌지를 판별하는 이진 분류 문제입니다. 주어진 Transformer 모델은 텍스트 메세지를 입력으로 받아 확률 값을 출력하며, 0.5를 기준으로 임계값을 설정하여 스팸 여부를 결정합니다.
작동원리
Transformer모델은 시퀀스 데이터를 처리하는데 특화된 딥러닝 아키텍처입니다. 기존의 순차적인 처리 방식과 달리, Transformer는 입력 시퀀스 전체를 동시에 처리하여 효율적인 학습과 예측을 가능하게 합니다. 이를 위해 주요한 구성 요소인 Attention 메커니즘을 사용합니다.
Attention은 입력 시퀀스의 각 위치에서 다른 위치와의 상호작용을 측정하여 가중치를 계산하는 메커니즘입니다. 이를 통해 모델은 주요한 정보에 집중하고, 문맥을 파악하여 입력 시퀀스르 효과적으로 이해할 수 있습니다. Transformer 모델은 Multi-head Attention 메커니즘을 사용하여 여러 개의 Attention 계산을 병렬로 수행하고, 결과를 결합하여 최종적인 표현을 생성합니다.
작동은 총 6단계를 거쳐 진행합니다. 전처리, 텍스트 벡터화, 토큰 및 위치 임베딩, Transformer 레이어, 분류기, 모델 학습 및 평가를 진행합니다.
전처리
데이터를 처리하기 전에 전처리 과정을 수행합니다. 전처리 단계에서는 구두점을 공백으로 대체하며, 텍스트를 소문자로 변환하며, 앞뒤 공백을 제거하는 작업을 수행합니다.
텍스트 벡터화
텍스트 모델에 입력하기 위해 텍스트 벡터화 과정을 수행합니다. 이를 위해 TensorFlow의 TextVectorization 레이어를 사용합니다. 이 레이어는 텍스트를 정수 인덱스로 변환하고, 시퀀스의 최대 길이로 패딩하여 일관된 길이로 맟춥니다.
토큰 및 위치 임베딩
Transformer 모델에는 토큰 임베딩과 위치 임베딩이 필요합니다. 토큰 임베딩은 텍스트 토큰을 고정 차원의 벡터로 변환하는 역활을 합니다. 위치 임베딩은 입력 시퀀스의 각 위치에 대한 정보를 추가합니다. 이러한 임베딩을 생성하기 위해 TokenAndPositionalEmbedding 레이러를 정의하고 사용합니다.
Transformer 레이어
Transformer 레이어는 입력 시퀀스를 처리하여 특성을 추출하는 역할을 합니다. Multi-Head Attention과 Feedforward Network로 구성되어 있으며, Layer Normalization을 사용하여 학습을 진행합니다. 이를 위해 Transformer Layer를 정의하고 사용합니다.
분류기
분류 작업을 위해 Global Average Pooling과 Dropout을 적용한 후 , 최종 출력을 위해 Dense를 사용합니다. 활성화 함수로는 Sigmoid 함수를 사용하여 확률값을 계산합니다.
모델 학습 및 평가
모델을 컴파일 한후, 테스트 데이터를 사용하여 모델의 성능을 평가하고, 손실, 정확도, 정밀도, 재현율,AUC 값을 출력합니다.
결과분석
Transformer 모델을 사용하여 스팸 메세지를 분류하는 방법에 대해 보고서를 작성하였습니다. 전처리, 텍스트 벡터화, 토큰 및 위치 임베딩, Transformer Layer, 분류기 등의 단계를 거쳐 모델을 학습시키고 평가하는 과정을 상세하게 다루었습니다. 이를 통해 스팸 메세지 분류 문제를 해결하기 위한 전체적인 절차를 이해할 수 있었습니다.
코드 설명
- ‘num_heads’는 Multi-Head Attention 에서 사용될 Head의 개수를 설정합니다.
- ‘embed_dim’ 은 임베딩 벡터의 차원을 나타냅니다.
- ‘ff_dim’은 Feedforward Network의 은닉층의 차원을 나타냅니다.
- ‘vocab_size’는 사용할 어휘 사전의 크기를 나타냅니다.
- ‘max_seq_len’ 은 입력 시퀀스의 최대 길이를 나타냅니다.
- ‘Learning_rage’는 모델의 학습률를 조정하는 파라미터입니다.
- 해당 코드를 통해 df에서 ‘Message’열을 추출하여 리스트 형태로 저장하며, ‘Category’열을 추출하여 리스트 형태로 저장하며 이를 타깃변수로 사용합니다. 레이블 인코더를 사용하여 카테고리에서의 ‘spam’을 1로, ‘ham’을 0으로 인코딩합니다.
데이터의 불균형을 보정하는 작업입니다.
proprocess_text 함수를 통해 데이터를 전처리합니다. 이후 layers.TextVectorization 레이어를 생성하여, 텍스트 데이터를 어휘로 변환하는 역할을 수행하게 됩니다
무작위로 선택한 text를 TextVectorization 레이어를 통해 벡터로 변환하고, 변환된 결과를 출력합니다. 이를 통해 어떻게 text가 벡터로 변환되는지 확인 할 수 있습니다.
TokenAndPositionalEmbedding은 layers.Layer 클래스를 상속하여 사용자가 layer를 정의하는 부분입니다. __init__ 메서드는 클래스의 생성자로, 층의 초기화를 담당합니다. call의 메서드는 층의 순방향 전파 연산을 정의합니다.이를 통해 임베딩 벡터를 생성하여, 생성된 벡터는 Transformer 모델의 입력으로 사용됩니다.
Transformer 레이어를 정의하는 부분입니다. MultiheadAttention 레이어를 생성하는 부분이며, inputs을 세번 사용하여 query, key, value를 받습니다.
call메서드는 층의 순방향 전파 연상을 통해, 입력으로 들어온 sequence에 대해 multi-head attention과 feed-forward 네트워크를 적용한 후, 정규화및 Residual Connection을 수행하여 출력을 반환합니다.Transformer 레이어를 정의하는 부분입니다. MultiheadAttention 레이어를 생성하는 부분이며, inputs을 세번 사용하여 query, key, value를 받습니다. call메서드는 층의 순방향 전파 연상을 통해, 입력으로 들어온 sequence에 대해 multi-head attention과 feed-forward 네트워크를 적용한 후, 정규화및 Residual Connection을 수행하여 출력을 반환합니다.
이후 model fit을 통해 학습을 진행합니다. 아래는 해당 model의 train결과 값입니다.
'AI > AI Project' 카테고리의 다른 글
| covid 데이터 선형회귀 (0) | 2023.09.13 |
|---|---|
| Spark MLLib Titanic Data - MulticlassClassification (0) | 2023.09.12 |
| Yolov5모델로 쓰레기 탐지하기 (0) | 2023.09.12 |
| LSTM으로 spam 데이터 판별 (0) | 2023.09.07 |
| 한국어 리뷰 감정 사전 구축하기 using soynlp and konlyp (0) | 2023.02.11 |