
Regularization이란?
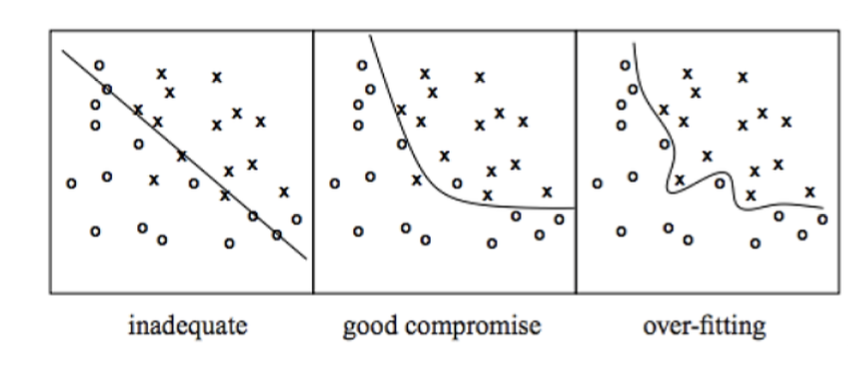
Overfitting을 피하기 위한 기법으로, 과적합을 예방하기 위한 Loss finction에 대한 추가 기준입니다. 이에 모델을 조금더 General하게 만들고자합니다.
Overfitting이란, 모델이 noise에 대해 높은 수용력을 가지며 기존 훈련 데이터에는 높은 성능을 가지지만, 새로운 예제에 대해선 그만큼의 성능을 보이지 못하는 경우를 의미합니다.
기본적인 Regularization의 수식은 다음과 같습니다.
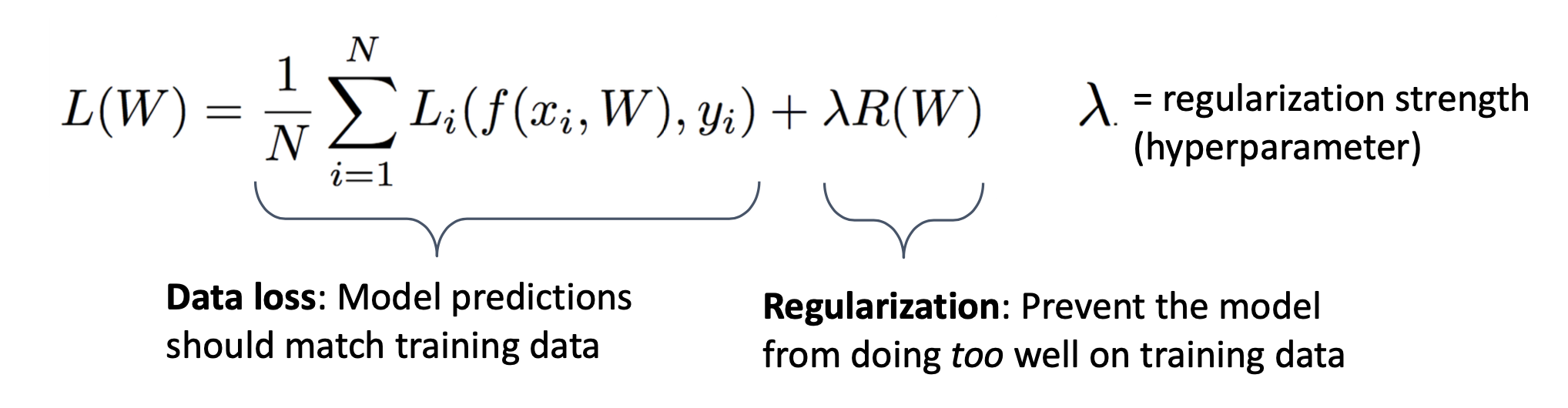
기존 Data loss를 통해 모델 예측을 하는 수식에 hyperparameter를 추가하여 overfitting을 피하도록 진행합니다.
이에 따라 L2 정규화와 L1정규화에 대해 설명하겠습니다.
L2 정규화란?
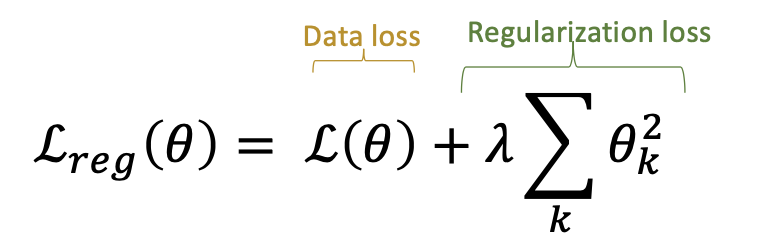
Ridge Regression이라고도 불리며, Loss function에 제곱한 가중치 값을 더해줌으로써 미분을 통해 back propagation 할 때 Cost 뿐만 아니라 가중치 또한 줄어드는 방식으로 학습을 진행 합니다. 특정 가중치가 비이상적으로 커지는 상황을 방지하고, Weight decay가 가능해지는 장점이 있습니다. 람다에 대해 클수록 value에 대한 penaly를 더 부가한다고 보시면 됩니다. 이에 필요한 Feature(이상치)에 대응하는 Weight를 0에 가깝게 만들 뿐, 0으로 만들지는 않습니다.
L1 정규화란?
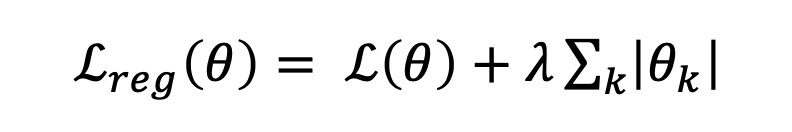
Ridge Regression이라고도 불리며, 가중치의 절대값을 더해주고, 편미분을 진행하면 부호만 남게 됩니다. 이에따라 불필요한 Feature에 대응하는 Weight를 정확히 0으로 만들어버려, 이에따라 결과적으로 몇몇 중요한 가중치만 남게 됩니다.
위 L1정규화와 L2정규화를 혼합하여 만드는 정규화를 Elastic net이라고 불립니다.
참고
https://seongyun-dev.tistory.com/52
[최적화] 가중치 규제 L1, L2 Regularization의 의미, 차이점 (Lasso, Ridge)
1. 수학적 최적화(Optimization)와 과적합 (Overfitting) 수학에서 최적화란, 특정 집합에 대한 목적 함수(Objective Function)를 최소화 혹은 최대화시키는 최적해 (파라미터)를 찾는 것을 말합니다. 머신러닝
seongyun-dev.tistory.com
https://junklee.tistory.com/29
L1, L2 Norm, Loss, Regularization?
정규화 관련 용어로 자주 등장하는 L1, L2 정규화(Regularization)입니다. 이번에는 단순하게 이게 더 좋다 나쁘다보다도, L1, L2 그 자체가 어떤 의미인지 짚어보고자합니다. 사용된 그림은 위키피디아
junklee.tistory.com
https://esj205.oopy.io/4b321662-5d02-4559-8677-7e974cf080a8
L1 정규화, L2 정규화
출처:
esj205.oopy.io
'AI > Concepts' 카테고리의 다른 글
| Clustering이란? (1) | 2023.12.11 |
|---|---|
| Batch normalization이란? (2) | 2023.12.07 |