
Batch란?
기본적으로 딥러닝에서 batch란, 전체 데이터에서 일부분을 칭하는 단어입니다. 이에 따라 학습의 효율성을 위해 전체 큰 데이터를 분할하여 학습을 하게 되는데 이를 batch단위로 쪼개 학습을 한다고 말합니다.
이때, Neural network의 depth가 깊어질수록, 즉 Layer가 많아질수록 "internal covariate shift" 현상이 발생합니다.
internal convariate shift 현상이란, 모델 학습 과정에서 Layer를 통과할 때마다 출력값의 데이터 분포는 Layer마다 다르게 나타나는 현상입니다.
왜 데이터의 분포가 달라지냐 묻는다면, 학습이 진행될수록 정규화를 하지 않으면 x,y의 학습폭이 다르게 나타날 수 있기 때문입니다.
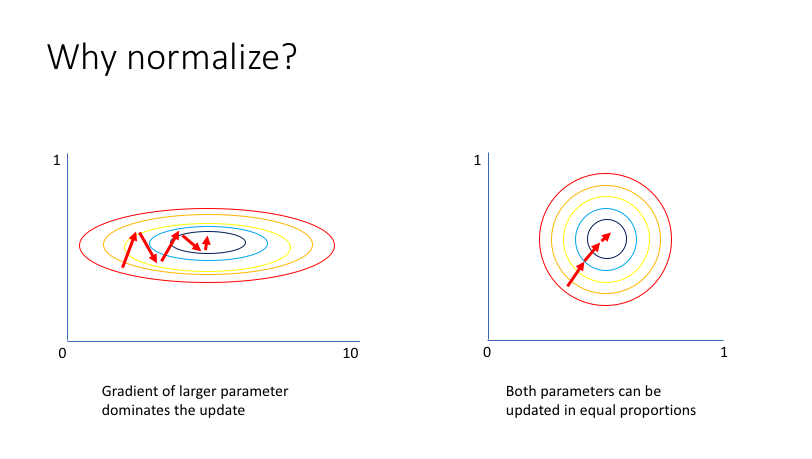
위 사진처럼 gradient를 진행할 때, 정규화를 하지 않으면 x의 폭과 y폭이 일정하지 않아, 일정하게 학습이 일어나지 않을 수 있습니다. 이에 따라 정규화를 진행합니다.
해당 Normalize를 하지 않는 학습과정을 시각화 한다면, 다음과 같이 분포가 나올 수 있습니다.
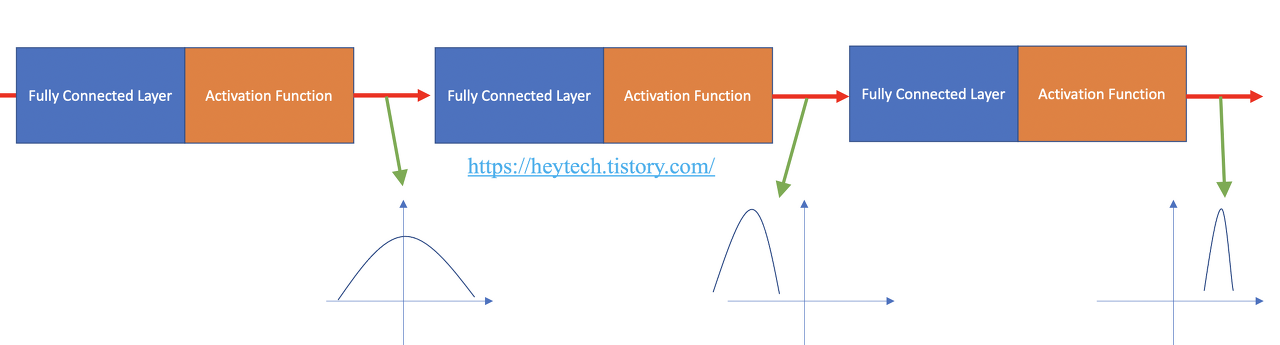
위 사진 처럼 기존 분포는 가우시안 분포를 띄지만 학습을 진행하고, 활성화 함수를 통해 나온 값의 분포가 점점 바뀌는 모습을 확인할 수 있습니다. 이런 문제를 해결하기 위해 Batch normalize를 진행합니다.


수식은 다음과 같습니다. 위 수식을 통해 배치 결과값의 평균값과 분산값을 각각 0과 1을 맞추기위해 진행합니다.

이후 베타와 감마값을 통해 활성화 함수로 값이 들어갈 때, 비선형 스케일을 잃지않도록 값을 조정하며 학습을 진행합니다.
결론
이런 Batch 정규화를 통해 다음과 같은 장점을 얻을 수 있습니다.
- Layer가 많아실수록 학습이 어려웠던 문제를 해결하며 학습이 일정하게 진행됩니다.
- overfitting을 피할 수 있습니다.
- Regularization 효과: 배치 정규화는 일종의 Regularization 효과를 가지고 있어 일반화 성능을 향상시킵니다.
- 큰 학습이 가능해집니다.
참고
https://wooono.tistory.com/227
[DL] 배치 정규화(Batch Normalization)
기존에는 Gradient Vanishing, Exploding 현상을 해결하고 학습을 안정화하기 위해서 새로운 활성화 함수를 찾거나 가중치를 초기화하는 방법을 사용했었다. 하지만, 배치 정규화를 통해서 보다 근본적
wooono.tistory.com
https://www.jeremyjordan.me/batch-normalization/
Normalizing your data (specifically, input and batch normalization).
In this post, I'll discuss considerations for normalizing your data - with a specific focus on neural networks. In order to understand the concepts discussed, it's important to have an understanding of gradient descent.
www.jeremyjordan.me
https://heytech.tistory.com/438
[Deep Learning] Batch Normalization(배치 정규화) 개념 및 장점
📌 들어가며 본 포스팅에서는 딥러닝 Generalization 기법 중 하나인 배치 정규화(Batch Normalization)에 대해 알아봅니다. 먼저, 데이터 정규화의 필요성에 대해 알아보고, Batch Normalization의 등장 배경인
heytech.tistory.com
'AI > Concepts' 카테고리의 다른 글
| Clustering이란? (1) | 2023.12.11 |
|---|---|
| Regularization, L1, L2 Regularization이란? (0) | 2023.12.06 |